共享存储服务NFS
为什么学NFS
一、为什么要学习NFS(网络文件系统)
- 资源共享便利性
- NFS允许在网络中的不同计算机之间共享文件系统。在企业或实验室环境中,这意味着可以将存储设备(如服务器上的大容量硬盘)中的文件提供给多个用户或其他计算机访问。例如,在一个科研团队中,实验数据存储在一台服务器上,通过NFS共享,团队中的各个研究人员可以在自己的工作站上方便地访问和处理这些数据,而不需要将数据在每台计算机上都进行复制。
- 集中化管理优势
- 对于系统管理员来说,NFS提供了一种集中管理文件的方式。可以在服务器端对文件的访问权限、存储配额等进行配置。比如,在一个公司的内部网络中,管理员可以通过NFS服务器设置不同部门员工对公司文档库的访问权限,销售部门可能只能读取产品介绍文件,而市场部门可以对宣传资料进行读写操作。
- 跨平台兼容性
- NFS支持多种操作系统,如Linux、Unix和Mac OS等。这使得在异构的网络环境中能够方便地实现文件共享。例如,一个开发团队中,部分开发人员使用Linux机器进行后端开发,部分使用Mac OS进行前端开发,通过NFS共享代码库,可以让不同操作系统的开发人员无缝协作。
二、什么是NFS(网络文件系统)
- 定义
- NFS是一种分布式文件系统协议,它允许用户通过网络在不同的计算机之间访问和共享文件。它基于客户端 - 服务器架构,服务器端将本地的文件系统导出,客户端可以挂载这些导出的文件系统,就好像它们是本地的文件系统一样进行操作。
- 工作原理
- 当客户端请求访问服务器上的文件时,它会发送一个NFS请求,这个请求包含了操作类型(如读取、写入、删除等)和文件路径等信息。服务器收到请求后,会根据请求进行相应的操作,并将结果返回给客户端。例如,当客户端想要读取服务器上一个名为“document.txt”的文件时,它会发送一个读取请求,服务器收到请求后,从本地磁盘读取文件内容,并将内容发送回客户端。
- 协议版本
- NFS有多个版本,如NFSv2、NFSv3和NFSv4等。NFSv2是比较早期的版本,功能相对简单。NFSv3在性能和功能上有所增强,例如支持更大的文件和更高效的文件传输。NFSv4是最新的主流版本,它集成了许多安全和性能方面的改进,如支持访问控制列表(ACL)和加密等功能。
三、怎么学习NFS
- 理论学习
- 阅读相关书籍和文档
- 可以从基础的网络和文件系统知识入手,了解操作系统中的文件系统结构,如Linux文件系统的inode(索引节点)、目录结构等概念。推荐阅读《Unix网络编程》等书籍,这些书籍涵盖了网络通信和文件系统相关知识,能够为理解NFS打下坚实的理论基础。同时,查看官方的NFS文档,如RFC(请求评议)文档,详细了解NFS协议的规范和细节。
- 学习网络通信基础
- 因为NFS是基于网络的文件系统协议,所以需要掌握网络通信的基础知识。包括TCP/IP协议族,如IP地址、端口号、传输层协议(TCP和UDP)等。理解网络拓扑结构和网络分层模型也很重要,例如知道在不同的网络环境(如局域网、广域网)中NFS的工作方式可能会受到的影响。
- 阅读相关书籍和文档
- 实践操作(以Linux为例)
- 服务器端配置
- 安装NFS服务器软件包,在常见的Linux发行版(如Ubuntu、CentOS)中,可以使用包管理器进行安装。例如,在CentOS中,使用“yum install nfs - utils”命令安装NFS相关工具。
- 配置NFS服务器,主要是通过编辑“/etc/exports”文件来指定要共享的目录和访问权限。例如,要共享“/data”目录,并且允许192.168.1.0/24网段的客户端进行读写访问,可以在“/etc/exports”文件中添加“/data 192.168.1.0/24(rw)”这一行内容。然后使用“exportfs - a”命令使配置生效。
- 客户端配置
- 在客户端上同样需要安装NFS相关软件包,如在Ubuntu中使用“apt - get install nfs - common”命令。
- 挂载服务器共享的文件系统,使用“mount - t nfs server_ip:/shared_directory local_mount_point”命令。例如,要挂载服务器192.168.1.100上共享的“/data”目录到本地的“/mnt/data”目录,可以使用“mount - t nfs 192.168.1.100:/data /mnt/data”命令。之后就可以像访问本地文件一样访问服务器上共享的文件了。
- 服务器端配置
- 故障排除与优化
- 故障排除
- 当遇到NFS无法正常工作的情况时,首先检查网络连接是否正常。可以使用“ping”命令测试客户端和服务器之间的连通性。如果网络正常,检查NFS服务器和客户端的配置是否正确,如“/etc/exports”文件的权限设置是否准确,客户端挂载命令是否正确等。查看NFS相关的日志文件也很重要,在Linux中,服务器端的日志文件通常位于“/var/log/messages”或“/var/log/syslog”中,可以从日志中获取错误信息来帮助解决问题。
- 优化
- 为了提高NFS的性能,可以从多个方面入手。在网络方面,确保网络带宽足够,避免网络拥塞。在服务器配置方面,可以调整NFS服务器的参数,如增加缓存大小等。同时,合理设置文件系统的属性,如文件块大小等也可以提高NFS的效率。
- 故障排除
NFS在企业的应用架构
在企业集群架构的工作场景中,NFS网络文件系统一般被用来存储共享视频、图片、静态文件,通常网站用户上传的文件也都会放在NFS共享里,例如BBS产品(论坛)产生的图片、附件、头像等,然后前端所有的节点访问静态资源时都会读取NFS存储上的资源。
阿里云等公有云平台的NAS就是云版的NFS服务应用。
像这个奔驰官网,需要展示大量的图片,动态图,html网页文件,这些都是存储在服务器上的。

- 存储共享基础架构
- 数据集中存储与共享:在企业中,NFS(网络文件系统)可以将存储设备(如磁盘阵列)挂载到多个服务器上。例如,在一个拥有多个Web服务器的企业数据中心,这些Web服务器需要共享HTML文件、图片、脚本等资源。通过NFS,将存储这些资源的存储设备挂载到各个Web服务器上,就可以实现数据的集中存储和共享。这样,当更新网站内容时,只需要在存储设备上更新文件,所有挂载该存储设备的Web服务器都可以访问到最新的文件,大大提高了工作效率。
- 多用户环境支持:在企业办公环境中,NFS可以用于共享文件服务器。员工可以通过NFS挂载共享文件夹,在不同的操作系统(如Linux和Windows通过相关的客户端软件)下访问公共文件。比如企业的文档管理系统,员工可以从自己的办公电脑上访问共享的文档库,进行文档的查看、编辑和保存操作,方便团队协作。
- 应用服务器集群架构
- 负载均衡与高可用性:在企业的应用服务器集群中,NFS可以提供共享存储。例如,在一个基于Java的企业级Web应用集群中,应用服务器(如Tomcat服务器)需要共享配置文件、应用程序代码等。NFS存储可以挂载到每个应用服务器节点,当有新的应用版本部署或者配置文件修改时,通过NFS可以确保所有节点获取到相同的更新。同时,在负载均衡场景下,多个服务器可以同时从NFS存储读取数据,提高系统的处理能力。并且如果一个应用服务器节点出现故障,其他节点可以继续使用NFS存储中的数据,保证了系统的高可用性。
- 数据库备份与恢复支持:对于企业数据库服务器,NFS存储可以作为备份存储目标。数据库管理员可以定期将数据库备份文件存储到NFS挂载的存储设备上。例如,在一个使用Oracle数据库的企业环境中,每天的全量备份和增量备份文件可以通过NFS存储到专门的备份存储设备中。在数据库出现故障需要恢复时,这些备份文件可以方便地从NFS存储中获取,加快恢复进程。
- 云计算与虚拟化环境
- 虚拟机共享存储:在企业的云计算数据中心或虚拟化环境中,NFS可以作为虚拟机的共享存储。例如,在VMware或KVM等虚拟化平台中,多个虚拟机可以通过NFS共享存储设备来存储虚拟机镜像文件、配置文件等。这样可以方便地对虚拟机进行克隆、迁移等操作。当需要创建新的虚拟机时,可以直接从NFS存储中获取镜像文件,提高了虚拟机的部署效率。
- 云计算存储服务后端支持:一些企业的私有云存储服务也可以利用NFS作为后端存储。例如,企业内部开发的对象存储服务,NFS存储可以用于存储对象数据。通过在NFS存储之上构建存储接口和管理系统,为企业内部用户提供类似于公有云存储的服务,如文件上传、下载、存储配额管理等功能。
企业生产集群为什么需要共享存储
- 数据一致性保障
- 在企业生产集群中,多个节点(服务器)通常协同工作来处理各种任务。例如,在一个电子商务平台的生产集群中,可能有多个Web服务器处理用户请求,多个应用服务器处理业务逻辑,还有数据库服务器负责数据存储和查询。如果这些服务器没有共享存储,每个节点都有自己独立的数据副本,那么当业务数据发生变化时(比如用户下单后更新商品库存),很难保证所有节点的数据同时更新且保持一致。
- 共享存储允许所有节点访问同一份数据。当一个节点对数据进行修改后,其他节点在访问该数据时可以立即看到更新后的结果。以金融交易系统为例,当一个交易服务器处理一笔转账业务并更新账户余额后,通过共享存储,其他相关的风险评估服务器、报表生成服务器等可以获取到最新的账户余额数据,从而做出准确的判断和操作,避免因数据不一致导致的业务错误。
- 高可用性和故障切换
- 企业生产环境要求系统具有高可用性,以减少因服务器故障等问题导致的业务中断时间。在一个集群环境中,如果没有共享存储,当一个节点出现故障时,将其任务转移到其他节点(故障切换)会变得非常复杂。因为每个节点的数据都是独立的,备份和恢复数据到替换节点的过程会很繁琐。
- 共享存储提供了一个统一的数据存储位置,使得故障切换更加容易。例如,在一个企业的邮件服务器集群中,如果一台邮件服务器出现故障,其他服务器可以通过共享存储快速接管故障服务器的任务。由于所有邮件数据都存储在共享存储中,新的服务器可以立即访问到用户的邮件账户信息、邮件内容等数据,从而实现无缝的故障切换,保障邮件服务的持续可用性。
- 资源高效利用和负载均衡
- 企业为了优化成本和提高效率,会在集群中实现负载均衡。多个节点共同分担工作负载,根据节点的性能和当前负载情况动态分配任务。共享存储可以使负载均衡更加高效。以内容分发网络(CDN)的边缘服务器集群为例,这些服务器需要存储大量的缓存内容(如图片、视频等)。
- 通过共享存储,当一个新的内容需要缓存时,任何一个负载较轻的服务器都可以将内容存储到共享存储中,其他服务器在需要时可以直接从共享存储中获取。这样可以避免每个服务器都重复存储相同的内容,节省了存储空间,并且可以根据服务器的负载情况灵活地分配存储任务,提高了整个集群的资源利用率。
- 数据集中管理和备份
- 对于企业来说,数据的集中管理和备份是非常重要的。在没有共享存储的情况下,每个节点的数据需要单独进行备份,这不仅增加了备份的复杂性,还可能因为备份策略不一致等问题导致数据丢失或恢复困难。
- 共享存储允许企业将数据集中存储在一个或几个存储设备上。这样,备份系统可以方便地对共享存储中的数据进行备份,例如,通过制定统一的备份策略,在夜间业务低谷期将整个共享存储中的数据备份到磁带库或其他备份介质上。而且,在数据恢复时,只需要从备份存储中恢复共享存储中的数据,然后所有节点都可以访问恢复后的数据,大大简化了数据管理和备份恢复的流程。
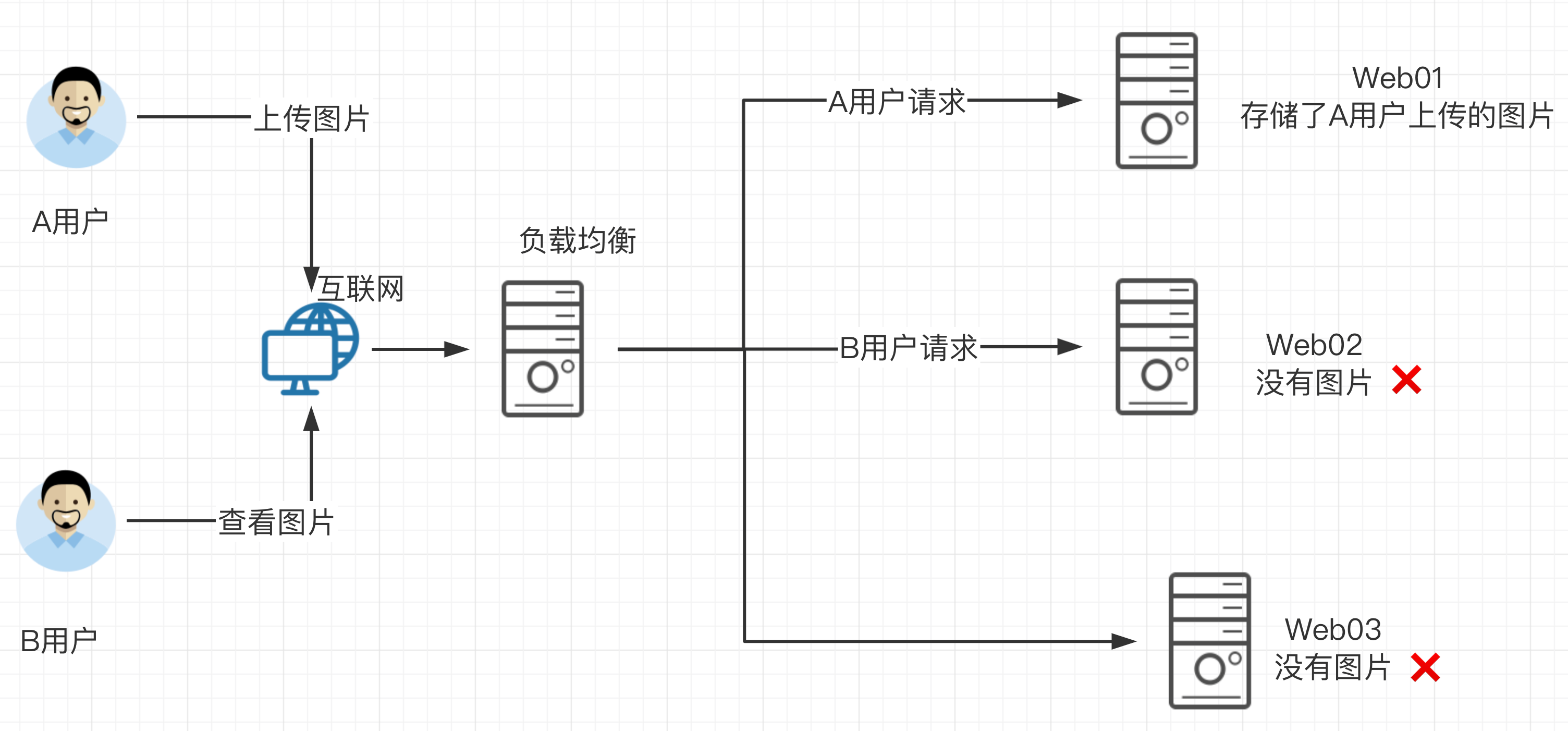
先看一下如果没有共享存储的问题
A用户上传图片到web01服务器,然后用户B访该图片,结果B的请求被负载均衡分发到了Web02,但是由于没有配置共享存储,web02没有该图片,导致用户B看不到该资源,用户心理很不爽呀。
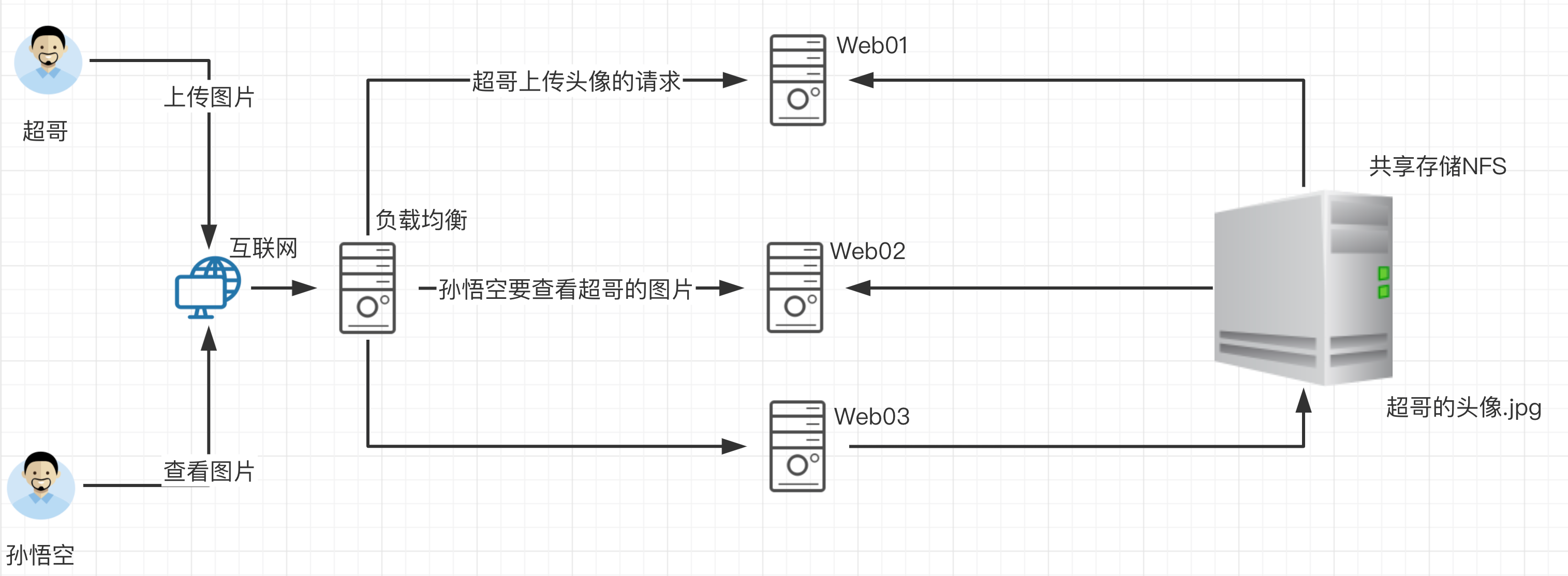
那么如果配置了共享存储,无论A用户上传的图片是发给了web01还是其他,最终都会存储到共享存储上,用户B再访问该图片的时候,无论请求被负载均衡发给了web01、web02、web03最终都会去共享存储上寻找资源,这样也就能够访问到资源了。
这个共享存储对于中小企业,也就是使用服务器配置NFS网络文件共享系统实现。
学习NFS的任务背景
问题来了,如何部署这个NFS网络文件系统呢?
我们来部署如下的操作
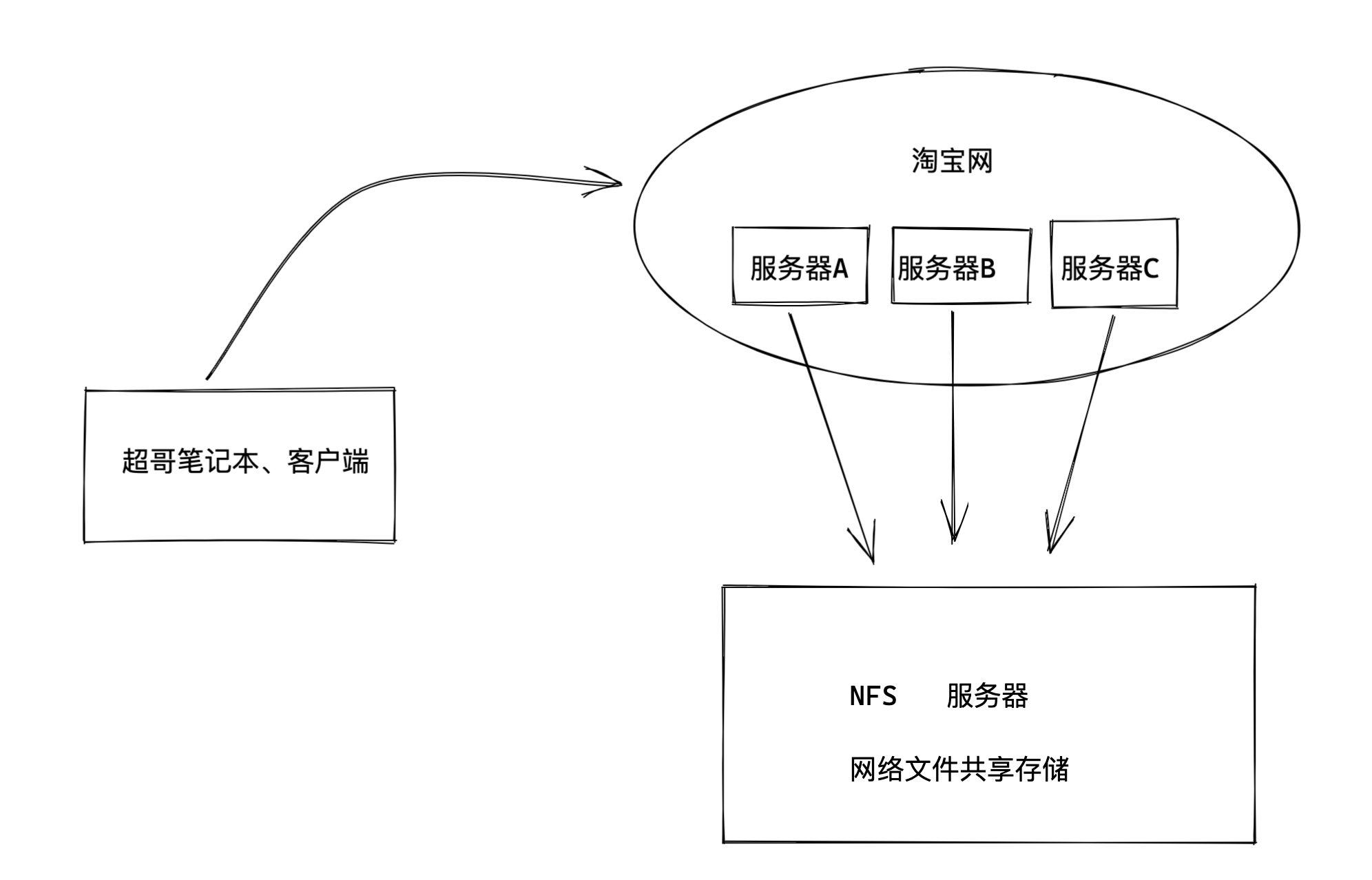
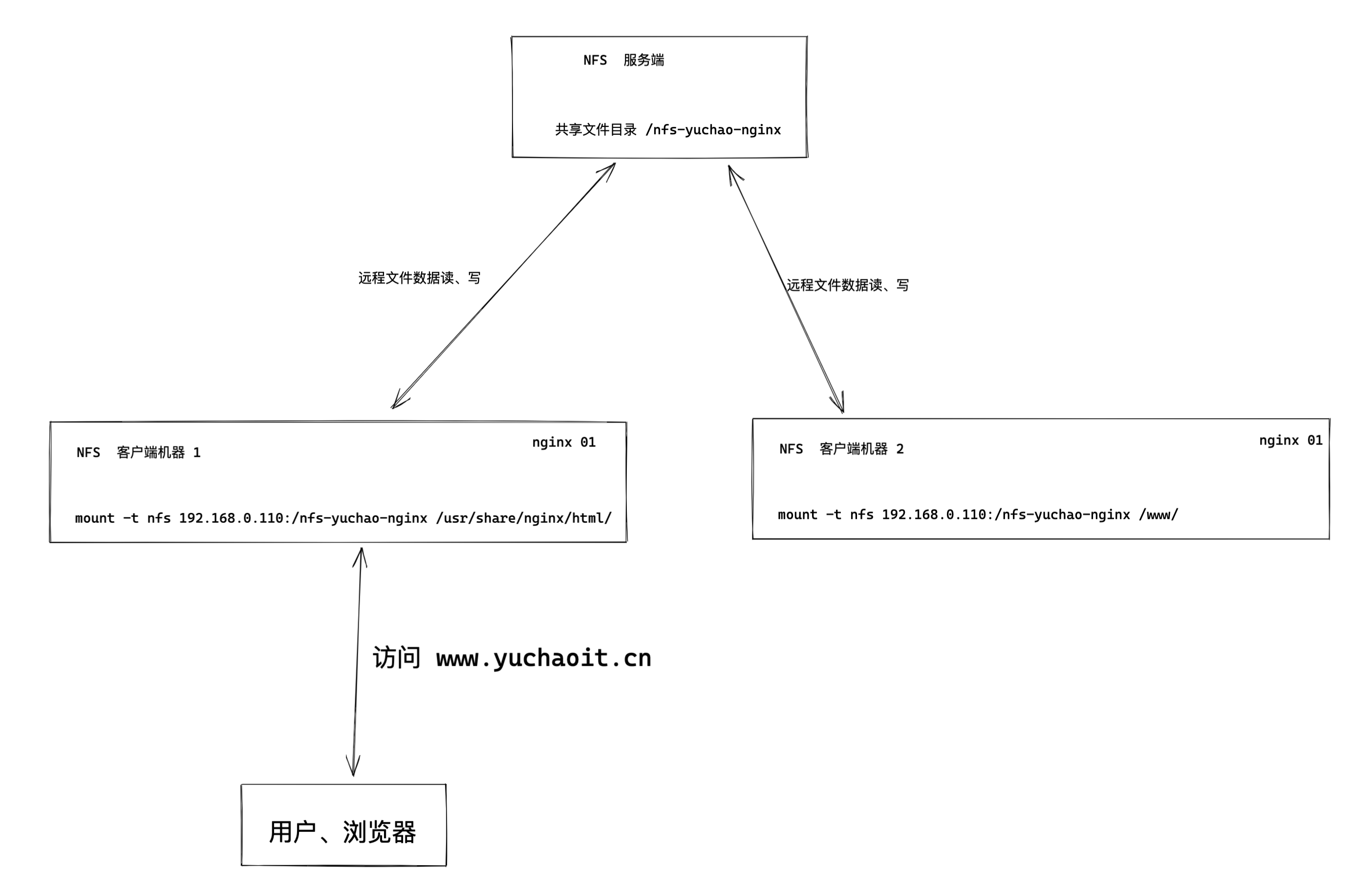
1.部署一台淘宝网服务器,网页服务器,提供静态网页的展示,该网站的html等静态资源远程存储在NFS服务器。
任务分析
1.淘宝网使用的nginx技术(web服务器部署技术)
2.部署NFS服务器,创建共享文件夹(提供静态文件),发布该共享目录,提供给web服务器使用。
最终效果
什么是共享存储
简单说就是将很多台服务器的数据,都可以保存在同一个存储服务器上。
这样可以在服务器集群内,数据统一存储到一台机器上,以实现共享存储。
这样在基于负载均衡的web集群下,用户无论请求哪一台机器都可以获取到同样的数据。
- 定义
- 共享存储是一种存储架构,它允许多个计算机系统(如服务器、工作站等)通过网络访问同一份存储资源。这些存储资源可以是硬盘阵列、存储区域网络(SAN)中的存储设备或者基于网络文件系统(NFS)、通用互联网文件系统(CIFS)等协议的存储卷。共享存储就像是一个公共的数据仓库,不同的计算机系统可以在授权范围内对其中的数据进行读取、写入、修改等操作。
- 工作原理
- 基于网络协议:以NFS为例,它使用远程过程调用(RPC)机制。当客户端(如服务器节点)需要访问共享存储中的文件时,它会向服务器端(提供共享存储的设备)发送RPC请求。服务器端收到请求后,根据请求的内容(如读取文件、写入文件等)进行相应的操作,然后将结果返回给客户端。这种方式使得客户端可以像访问本地文件系统一样访问共享存储中的文件。
- 存储设备连接方式:在存储区域网络(SAN)的共享存储场景中,存储设备通过光纤通道(FC)或以太网等连接方式与服务器相连。服务器使用专门的存储协议(如iSCSI)来识别和访问存储设备。通过这些连接和协议,服务器可以将存储设备中的存储卷挂载到本地,从而实现对共享存储的访问。
- 常见类型
- 网络附属存储(NAS):这是一种常见的共享存储设备。它本质上是一个带有存储功能的小型服务器,通过以太网连接到企业网络。NAS设备运行专门的操作系统(如基于Linux的操作系统),并提供文件共享服务。企业用户可以通过NFS、CIFS等协议从不同的计算机访问NAS设备中的文件。例如,在一个小型企业办公室环境中,员工可以通过NAS设备共享文档、图片等文件,方便团队协作。
- 存储区域网络(SAN):SAN通常用于企业级的大规模存储需求。它由存储设备、交换机和服务器组成。SAN提供了高速的数据传输通道,使服务器能够快速地访问存储设备中的数据。例如,在一个数据密集型的企业,如银行的数据中心,SAN可以用来存储大量的客户账户信息、交易记录等。服务器通过光纤通道或iSCSI协议连接到SAN,实现对存储资源的高效访问。
- 分布式文件系统(DFS):如CephFS、GlusterFS等,这些分布式文件系统通过在多个存储节点之间分配和管理数据,实现共享存储。以GlusterFS为例,它将多个存储节点组成一个存储集群,通过分布式哈希表等技术来管理文件的存储位置。当用户访问文件时,GlusterFS会根据文件的存储位置信息将请求路由到相应的存储节点,实现对文件的高效访问。这种分布式共享存储方式可以提供高扩展性和高可用性。
什么是NFS
network file system 网络文件系统
NFS主要使用在局域网下,让不同的主机之间可以共享文件、或者目录数据
主要用于linux系统上实现文件共享的一种协议,其客户端主要是Linux
没有用户认证机制,且数据在网络上传送的时候是明文传送,一般只能在局域网中使用
支持多节点同时挂载及并发写入
NFS使用场景

1.在服务器集群下,多台web服务器的图片、HTML、视频等静态资源,全都统一保存在NFS服务器上
2.以及NFS服务器也可以当做备份服务器
NFS架构图
NFS程序运行后,产生如下组件
- RPC(Remote Procedure Call Protocol): 远程过程调用协议,它是一种通过网络从远程计算机程序上请求服务,不需要了解底层网络技术的协议。 -
- rpcbind //负责NFS的数据传输,远程过程调用 tcp/udp协议 端口111
- nfs-utils //控制共享哪些文件,权限管理
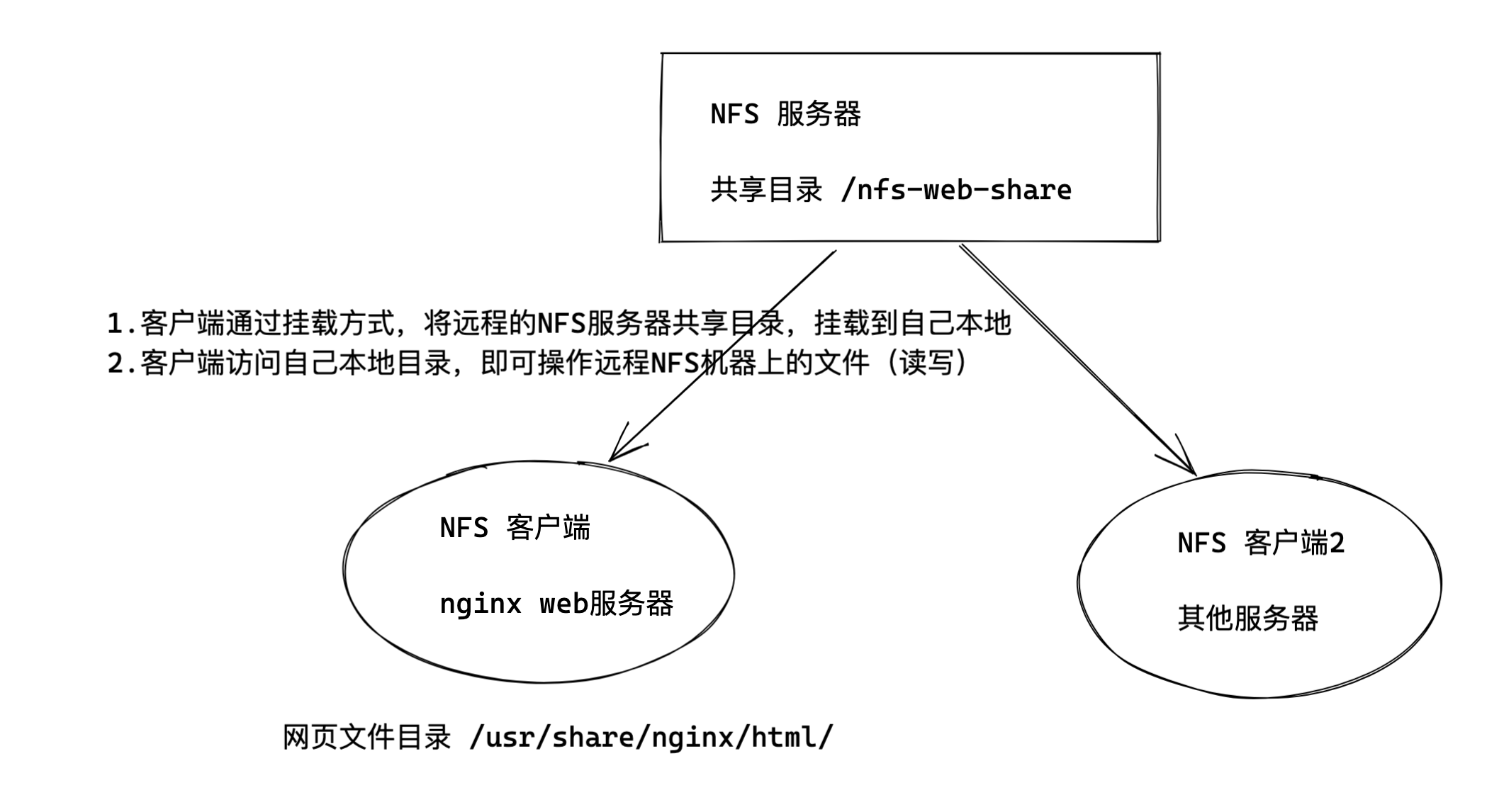
NFS采用客户端/服务器架构,其架构图及各部分说明如下:
安装nfs服务端,ubuntu
yc-ubuntu-24 nfs服务端,提供数据
# centos下,nfs服务端,nfs-utils
# ubuntu下,nfs服务端,nfs-kernel-server
root@yc-ubuntu-24 ~# apt install nfs-kernel-server
ubuntu-96 提供web服务器展示 ,nginx,挂载nfs
客户端,windows,macos 浏览器,
客户端
- NFS文件系统:位于虚拟文件系统(VFS)之下,是Linux内核中的一个文件系统,与本地文件系统类似,通过VFS接收用户和应用程序对文件的操作请求,并将其转换为NFS协议的请求格式。
- RPC模块:位于客户端的Linux内核中,负责将NFS文件系统的请求封装成RPC调用,并通过网络发送给NFS服务器。同时,它也负责接收服务器返回的结果,并将其转换为NFS文件系统能够理解的格式。
服务器端
- NFS守护进程(NFSD):是NFS服务的核心,监听在2049/tcp和2049/udp端口上,接收客户端通过RPC发送的请求,对请求进行解析和处理,然后将处理结果通过RPC返回给客户端。
- 本地文件系统:NFS服务器最终还是要将数据存储起来的,通常借助本地文件系统(如Ext4、XFS等)来存储共享的文件和目录。NFSD在处理客户端请求时,会调用本地文件系统的接口来进行实际的文件操作。
- idmapd进程:实现用户帐号的集中映射,把所有的帐号都映射为NFSNOBODY,但在访问时却能以本地用户的身份去访问,确保用户在访问共享文件时的权限和身份验证。
- mountd进程:用于验证客户端是否在允许访问此NFS文件系统的客户端列表中,若在则允许访问并发放一个令牌,客户端持令牌去找nfsd进行后续操作,其服务端口是随机的,由rpc服务(portmapper)提供随机端口号。
- portmapper进程:NFS服务器的rpc服务,监听于111/TCP和111/UDP套接字上,用于管理远程过程调用(RPC),为mountd等其他服务提供端口映射服务。
网络传输
- RPC协议:位于TCP/IP协议之上,是一个应用层的协议,用于客户端和服务器之间的通信,负责在网络上传输NFS请求和响应。它使得客户端的函数调用与本地函数调用类似,客户端与服务端是一一对应的,通过网络将请求传到服务端,并调用服务端注册的相应接口。
- TCP/IP协议:为NFS的RPC协议提供底层的网络传输服务,确保数据在客户端和服务器之间的可靠传输。
NFS服务端进程
- 功能概述
/usr/sbin/rpc.nfsd是NFS(Network File System)服务器的核心守护进程之一。它主要负责处理来自NFS客户端的请求,这些请求涉及文件系统操作,如读取、写入、文件属性查询等。它通过RPC(Remote Procedure Call)机制来接收和处理客户端请求。
- 工作原理
- NFS是基于客户端 - 服务器模型的分布式文件系统。当NFS客户端想要访问服务器上的共享文件系统时,它会通过网络发送RPC请求。
rpc.nfsd守护进程在服务器端监听这些请求,并根据请求的类型(如文件读取请求、写入请求等),与服务器的文件系统进行交互。 - 例如,当客户端请求读取一个文件时,
rpc.nfsd会从服务器的本地文件系统中获取该文件的内容,并将其通过网络发送回客户端。它会验证客户端的权限,确保请求的操作是在服务器配置的权限范围之内,比如检查客户端是否有对请求文件的读或写权限。
- NFS是基于客户端 - 服务器模型的分布式文件系统。当NFS客户端想要访问服务器上的共享文件系统时,它会通过网络发送RPC请求。
- 与其他组件的关系
- 它与
rpc.mountd守护进程密切合作。rpc.mountd主要负责处理客户端挂载NFS共享目录的请求,而rpc.nfsd则负责处理挂载后的文件系统操作请求。 - 同时,它也依赖于底层的网络协议(通常是UDP或TCP)来进行通信。在NFS的配置文件(如
/etc/exports)中定义的共享设置会影响rpc.nfsd的行为,这些设置决定了哪些目录可以被共享以及客户端访问这些共享目录的权限。
- 它与
- 重要性
- 对于NFS服务器的正常运行至关重要。如果
rpc.nfsd没有正常运行或者出现故障,客户端将无法正常访问服务器上的共享文件系统。例如,在一个企业的办公环境中,如果NFS服务器使用rpc.nfsd来提供文件共享服务,员工在客户端机器上就无法读取或修改共享文件夹中的文件,这会严重影响工作效率。
- 对于NFS服务器的正常运行至关重要。如果
nfs服务端命令
- /usr/sbin/exportfs
- 功能:
- 这个命令用于维护NFS(网络文件系统)服务器的共享文件系统表。它可以用来设置、修改或者显示NFS服务器共享目录的信息。例如,当你在
/etc/exports文件中添加或修改了共享目录的配置后,需要运行exportfs -a命令来使新的配置生效。-a参数表示重新导出所有的共享目录。
- 这个命令用于维护NFS(网络文件系统)服务器的共享文件系统表。它可以用来设置、修改或者显示NFS服务器共享目录的信息。例如,当你在
- 工作方式:
- 它读取
/etc/exports文件的内容,该文件包含了NFS服务器要共享的目录以及客户端访问这些目录的权限等信息。根据文件中的配置,exportfs命令会更新内核中的共享表,使得NFS服务器能够按照配置来提供共享服务。
- 它读取
- 示例:
- 假设你在
/etc/exports文件中添加了一个新的共享目录/data/share,权限设置为允许所有客户端读写(*(rw))。修改完成后,运行sudo exportfs -a,exportfs命令就会将这个新的共享目录添加到内核的共享表中,这样客户端就可以访问这个新的共享目录了。
- 假设你在
- 功能:
- /usr/sbin/nfsdcld
- 功能:
nfsdcld主要用于NFS动态客户端配置。它可以帮助NFS服务器管理和更新客户端的相关配置信息,特别是在涉及到动态的网络环境或者客户端频繁变化的场景中。
- 工作方式:
- 它与NFS服务器的其他组件协作,通过读取和更新特定的配置文件或者数据库来维护客户端配置。例如,当有新的客户端加入网络并尝试访问NFS服务器时,
nfsdcld可能会参与到验证和配置该客户端的过程中。
- 它与NFS服务器的其他组件协作,通过读取和更新特定的配置文件或者数据库来维护客户端配置。例如,当有新的客户端加入网络并尝试访问NFS服务器时,
- 示例:
- 在一个企业网络中,有新的部门加入,新的客户端机器需要访问NFS服务器。
nfsdcld可以协助更新服务器端关于这些新客户端的配置信息,比如权限设置等。不过在很多简单的NFS配置场景中,这个服务可能不会被频繁使用,因为很多配置是静态的。
- 在一个企业网络中,有新的部门加入,新的客户端机器需要访问NFS服务器。
- 功能:
- /usr/sbin/nfsdclddb
- 功能:
- 它与NFS动态客户端配置数据库相关。它可能用于存储、管理和检索NFS客户端配置相关的数据,比如客户端的访问权限历史、配置变更记录等信息。
- 工作方式:
- 具体的内部工作机制可能涉及到数据库操作,如存储客户端的IP地址、访问权限级别、共享目录访问历史等信息。这些数据可以用于审计、故障排查或者动态配置调整等目的。
- 示例:
- 当需要审计NFS服务器的使用情况,查看哪些客户端在什么时间访问了哪些共享目录,以及进行了何种操作时,
nfsdclddb所维护的数据就可以提供这些信息。不过,它的使用通常需要配合其他的管理工具或者命令来进行数据提取和分析。
- 当需要审计NFS服务器的使用情况,查看哪些客户端在什么时间访问了哪些共享目录,以及进行了何种操作时,
- 功能:
- /usr/sbin/nfsdclnts
- 功能:
- 这个命令可能用于管理和查看NFS客户端的相关信息。它可能提供关于客户端的连接状态、访问的共享目录、权限等信息。
- 工作方式:
- 它与NFS服务器的其他守护进程(如
rpc.nfsd和rpc.mountd)进行通信,获取客户端的相关信息。例如,它可以查询哪些客户端当前正在访问NFS服务器,以及它们正在访问的共享目录和进行的操作。
- 它与NFS服务器的其他守护进程(如
- 示例:
- 当系统管理员怀疑有未经授权的客户端访问NFS服务器时,可以使用
nfsdclnts来查看所有连接的客户端信息,包括它们的IP地址和访问的共享目录,从而进行安全检查和处理。
- 当系统管理员怀疑有未经授权的客户端访问NFS服务器时,可以使用
- 功能:
- /usr/sbin/rpc.mountd
- 功能:
rpc.mountd主要负责处理NFS客户端挂载服务器共享目录的请求。当客户端想要访问NFS服务器上的共享文件系统时,首先需要通过rpc.mountd来挂载相应的共享目录。
- 工作方式:
- 它读取
/etc/exports文件中的共享目录配置信息,根据这些信息来决定是否允许客户端挂载请求。当客户端发送挂载请求时,rpc.mountd会验证请求的合法性,包括检查客户端的权限、请求挂载的目录是否在共享列表中等。如果验证通过,它会为客户端建立挂载点,使得客户端可以访问共享目录。
- 它读取
- 示例:
- 客户端发送请求挂载NFS服务器上的
/data/share共享目录。rpc.mountd会检查客户端是否有访问该目录的权限(根据/etc/exports文件中的配置),如果权限允许,它会完成挂载操作,之后客户端就可以像访问本地文件系统一样访问/data/share目录了。
- 客户端发送请求挂载NFS服务器上的
- 功能:
- /usr/sbin/rpc.nfsd
- 功能:
- 前面已经介绍过,
rpc.nfsd是NFS服务器的核心守护进程之一,负责处理来自NFS客户端的文件系统操作请求。这些请求包括文件的读取、写入、删除、文件属性查询等操作。
- 前面已经介绍过,
- 工作方式:
- 它通过RPC(远程程序调用)机制接收客户端的请求,然后与服务器的本地文件系统进行交互来完成请求的操作。例如,当客户端请求读取一个文件时,
rpc.nfsd会从服务器的本地文件系统中获取文件内容,并将其发送回客户端。同时,它会根据服务器配置的权限设置来验证客户端的请求是否合法。
- 它通过RPC(远程程序调用)机制接收客户端的请求,然后与服务器的本地文件系统进行交互来完成请求的操作。例如,当客户端请求读取一个文件时,
- 示例:
- 客户端请求向NFS服务器上的共享目录中的一个文件写入数据。
rpc.nfsd会首先检查客户端是否有写权限,然后将客户端发送的数据写入服务器的本地文件系统中的相应文件中。
- 客户端请求向NFS服务器上的共享目录中的一个文件写入数据。
- 功能:
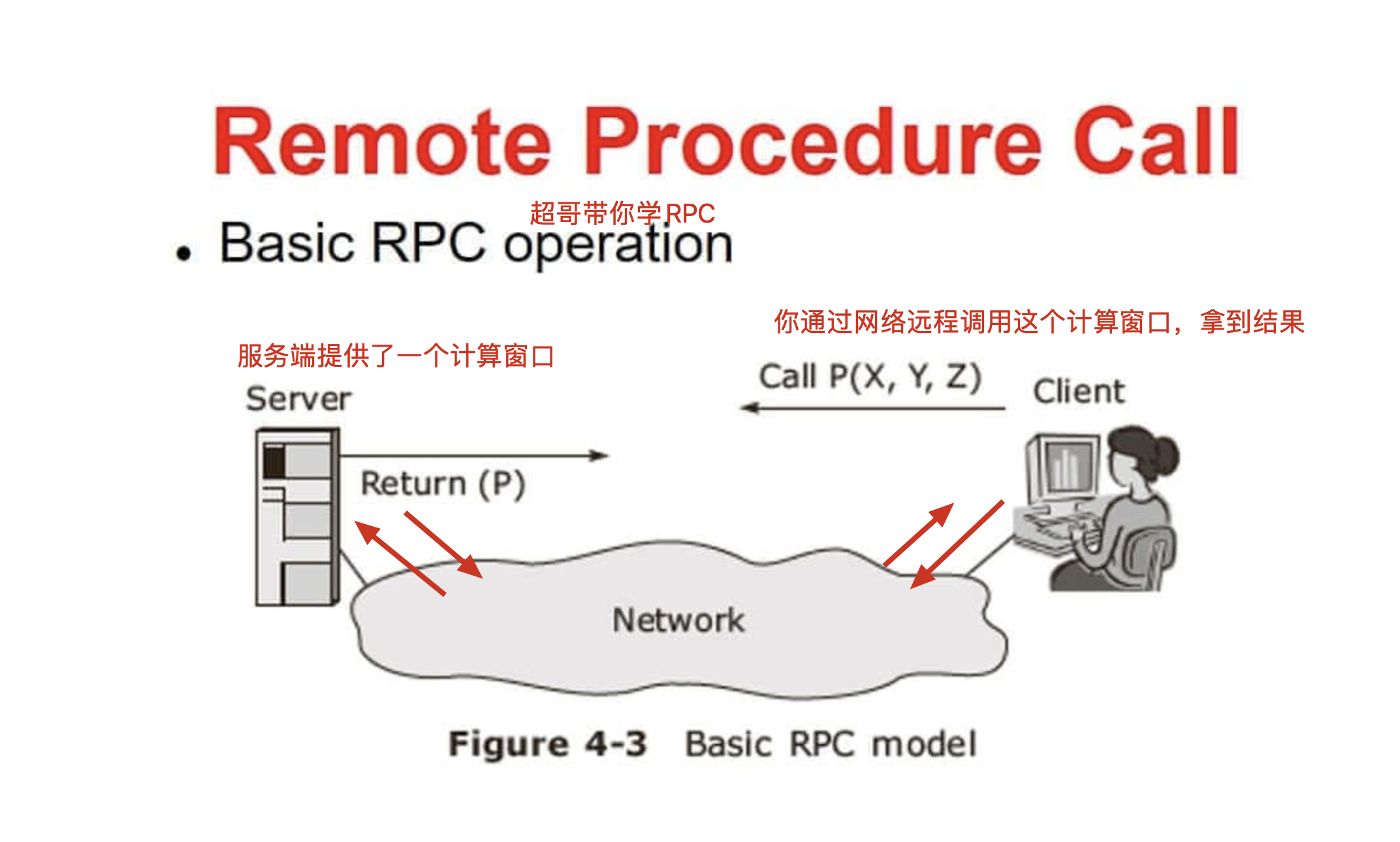
简单理解RPC
RPC的定义
- RPC全称是Remote Procedure Call(远程过程调用)。简单来说,它是一种计算机通信协议,允许一个程序(通常是客户端程序)在不同的地址空间(比如在另一台计算机上)调用另一个程序(通常是服务器程序)中的过程或函数,就好像这个过程或函数是本地调用一样。
``` 本地调用 root@yc-ubuntu-24 ~# cat halo.py import random print(f"本次随机数是:{random.randint(1,10)}")
root@yc-ubuntu-24 ~# cat halo.py import random
def t_random():
print(f"本次随机数是:{random.randint(1,10)}")t_random() root@yc-ubuntu-24 ~# root@yc-ubuntu-24 ~# root@yc-ubuntu-24 ~# vim halo.py root@yc-ubuntu-24 ~# python3 halo.py 本次随机数是:10 root@yc-ubuntu-24 ~# python3 halo.py 本次随机数是:4 root@yc-ubuntu-24 ~# python3 halo.py 本次随机数是:8
```
- 例如,想象你在自己的家里(客户端),通过电话(RPC协议)向商店(服务器)订购商品。你不需要亲自去商店,只需要告诉店员(服务器程序)你想要什么,店员就会为你处理订单(执行函数),然后把结果(商品或者相关信息)反馈给你。
- RPC的工作原理
- 存根(Stub)的概念:
- 当客户端程序想要调用远程服务器上的函数时,它实际上是调用一个本地的“存根”函数。这个存根函数就像是一个代理,它知道如何把客户端的请求通过网络发送到服务器。例如,在NFS中,客户端的
rpc.nfsd调用就是通过这样的存根函数来和服务器通信的。
- 当客户端程序想要调用远程服务器上的函数时,它实际上是调用一个本地的“存根”函数。这个存根函数就像是一个代理,它知道如何把客户端的请求通过网络发送到服务器。例如,在NFS中,客户端的
- 参数传递和打包:
- 客户端把要调用的函数名称和参数打包成一个消息。这个消息就像一个包裹,里面包含了详细的“订单信息”,比如函数名称就像是你要买的商品名称,参数就是商品的数量、规格等细节。然后这个消息通过网络协议(如TCP/IP)发送到服务器。
- 服务器处理:
- 服务器接收到这个消息后,会解开包裹(解包),找到对应的函数并使用客户端传来的参数执行这个函数。还是用商店的例子,店员(服务器)收到你的订单后,会根据订单内容(函数名称和参数)准备商品(执行函数)。
- 结果返回:
- 服务器把函数执行的结果再打包成一个消息,通过网络发送回客户端。客户端接收到这个消息后,解包得到结果,就好像这个函数是在本地执行得到的结果一样。在商店的例子中,店员把商品(结果)寄给你(客户端),你收到后就完成了整个购物(函数调用)过程。
- RPC在NFS中的应用
- 在NFS(网络文件系统)中,客户端和服务器之间的通信大量使用了RPC。例如,当客户端想要读取服务器上共享目录中的一个文件时,它会通过RPC机制向服务器发送一个“读取文件”的请求。
- 具体来说,客户端的
rpc.nfsd调用会把请求(如文件名、读取位置等参数)打包发送给服务器的rpc.nfsd守护进程。服务器的rpc.nfsd接收到请求后,会根据请求从本地文件系统读取文件内容,然后把结果打包返回给客户端。这样,客户端就能获取到文件内容,而整个过程对于用户来说就像是在本地读取文件一样。- RPC的优势
- 分布式系统的高效协作:
- 它使得在分布式系统中不同计算机上的程序能够方便地协作。不同的程序可以分布在网络中的不同节点上,通过RPC来共享功能和数据,而不需要把所有的程序都放在同一台计算机上。
- 简化程序开发:
- 对于开发者来说,RPC让他们可以像开发本地程序一样开发分布式程序。他们不需要过多地关注网络通信的细节,只需要按照规定的接口(函数名称和参数)来调用远程函数即可。就好像你在开发购物程序时,不需要关心电话通信(网络通信)的细节,只需要知道如何和店员(服务器函数)沟通订单(函数调用)就行。
什么是RPC
- 定义
- RPC(Remote Procedure Call)即远程过程调用,是一种计算机通信协议。它允许一台计算机程序(客户端)调用另一台计算机(服务器)上的子程序或函数,就好像这个调用是本地调用一样。简单来说,RPC使得程序能够在分布式计算环境中,轻松地调用位于远程系统中的代码逻辑,而不需要程序员去详细处理网络通信等复杂的底层细节。
- 工作原理
- 客户端部分:当客户端程序想要调用一个远程函数时,它会像调用本地函数一样发起一个请求。这个请求会被封装成符合RPC协议的消息格式。消息中包含了要调用的函数名称、参数等信息。例如,在一个分布式的订单管理系统中,客户端(可能是一个Web应用前端)需要查询远程服务器上的订单状态,它会把“查询订单状态”这个函数名以及订单编号等参数封装起来。
- 网络传输部分:封装好的RPC消息通过网络传输到服务器端。这通常依赖于底层的网络协议,如TCP/IP。在传输过程中,RPC协议会确保消息能够准确地到达目标服务器,并且能够处理可能出现的网络问题,如消息丢失、重复等情况。
- 服务器端部分:服务器端接收到RPC消息后,会对消息进行解析。它会根据消息中的函数名称找到对应的函数实现,然后使用消息中的参数来执行这个函数。在上述订单管理系统的例子中,服务器端会找到“查询订单状态”这个函数的实现代码,然后根据传入的订单编号去数据库中查询状态。执行完函数后,服务器端会把结果(如订单的状态信息)封装成RPC响应消息,再通过网络返回给客户端。
- 优势
- 简单性和易用性:对于程序员来说,RPC使得编写分布式应用程序变得更加容易。他们可以像编写本地应用程序一样调用远程函数,不需要深入了解网络编程的细节,如套接字编程、字节流的处理等。这样可以大大提高开发效率,减少开发复杂分布式系统的难度。
- 分布式系统的支持:在企业级的分布式应用中,如微服务架构,不同的服务可能部署在不同的服务器上。RPC提供了一种有效的通信机制,使得各个服务之间能够相互调用。例如,在一个电商平台的微服务架构中,用户服务可能需要调用订单服务来获取用户的订单信息,RPC可以方便地实现这种跨服务的调用。
- 可维护性和可扩展性:由于RPC将远程调用抽象成类似于本地调用的方式,当系统需要扩展或者修改时,比如增加新的服务或者更新函数的实现,只需要在相应的服务器端进行修改,而客户端的调用方式基本不变。这样可以降低系统维护的复杂性,提高系统的可扩展性。
- 应用场景
- 分布式计算:在科学计算领域,如大规模的数值模拟、数据分析等,计算任务可能会被分配到多个计算节点上。RPC可以用来在这些节点之间进行通信,例如一个节点可能需要调用另一个节点上的计算子函数来完成整个计算任务。
- 微服务架构通信:如前面提到的电商平台例子,在微服务架构中,各个微服务之间需要频繁地通信和协作。RPC是一种常用的通信方式,它可以实现服务之间的高效调用,比如产品服务与库存服务之间的交互,通过RPC可以快速地查询产品库存情况。
运维工具和RPC
- Ansible
- 概述:Ansible是一个自动化运维工具,在其内部机制中使用了RPC概念。它通过SSH协议进行通信,在一定程度上可以看作是一种基于SSH的RPC实现。
- 工作方式与RPC关联:当Ansible在管理节点上执行一个任务(如在被管理节点上安装软件包)时,它会在本地构建一个任务请求,这个请求包含了要执行的模块名称(如
yum模块用于在CentOS系统上安装软件)、参数(如软件包名称)等信息。然后通过SSH将这个请求发送到被管理节点。被管理节点上的Ansible执行环境接收到请求后,就相当于接收到一个远程调用请求,它会解析这个请求并执行相应的操作,最后将结果返回给管理节点。这整个过程类似于RPC,管理节点是客户端,被管理节点是服务器,通过网络(SSH)进行远程调用。 - 应用场景示例:在大规模服务器部署场景中,假设要在100台服务器上安装Nginx。通过Ansible,可以在管理节点上编写一个简单的playbook(任务脚本),其中包含一个任务,使用
yum或apt模块(根据服务器操作系统)来安装Nginx。Ansible会将这个安装任务作为“远程调用”发送到每一台服务器,服务器执行安装操作并返回结果,这样就可以高效地完成大规模的软件安装任务。
- SaltStack
- 概述:SaltStack是另一个流行的自动化运维工具,它也运用了类似RPC的通信机制。它有自己的通信协议,用于在主服务器(Master)和从服务器(Minion)之间传递信息。
- 工作方式与RPC关联:SaltStack的Master节点可以看作是客户端,Minion节点看作是服务器。当Master需要在Minion上执行一个任务(如执行一个命令或者配置一个服务)时,Master会发送一个包含任务指令的消息到Minion。这个消息包含了要调用的函数(如
cmd.run用于在Minion上运行一个命令)和参数(如要运行的具体命令)。Minion接收到消息后,会解析并执行相应的操作,就像处理一个远程调用一样,然后将结果返回给Master。 - 应用场景示例:在配置管理场景中,SaltStack的Master可以发送一个配置任务到所有的Minion节点,例如配置一个监控代理(如Zabbix Agent)的参数。Master发送包含配置任务指令的消息到Minion,Minion执行配置操作并反馈结果,从而实现对大量服务器的统一配置管理。
- Puppet(部分涉及)
- 概述:Puppet是一个用于配置管理和自动化部署的工具。虽然它主要基于拉取模型(客户端主动从服务器拉取配置信息),但在某些通信和执行机制方面也涉及类似RPC的概念。
- 工作方式与RPC关联:在Puppet中,当客户端(Agent)需要获取最新的配置或者执行一个配置任务时,它会与服务器(Master)进行通信。服务器会发送一些指令(如如何配置一个特定的服务),这些指令在客户端被执行的过程类似于远程调用。客户端会根据接收到的指令,调用自身的模块或者工具来执行配置操作,然后将执行结果反馈给服务器。
- 应用场景示例:在企业环境中,当需要更新所有服务器上的防火墙规则时,Puppet的服务器可以发送新的防火墙配置指令到客户端。客户端接收到这些指令后,调用本地的防火墙配置工具(如
iptables或firewalld)来执行配置更新,这一过程体现了类似RPC的远程指令执行机制。
RPC(Remote Procedure Call)远程过程调用,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。
下面举个简单的例子来理解 RPC。
远程过程调用,相对应的就是,本地过程调用。
rpc一般是开发中的网络编程知识
1.于超老师本地写好了一个代码文件,如hello-world.py ,本地运行该程序,这就是本地过程调用(执行程序,拿到结果)
2.远程过程调用
于超老师在将代码文件放在远程服务器上,在自己笔记本上,远程调用、执行该代码文件,执行结果会通过网络把数据发回来,这就是远程过程调用
Python实现rpc
root@yc-ubuntu-24 ~# cat halo.py
import random
def t_random():
print(f"本次随机数是:{random.randint(1,10)}")
t_random()
root@yc-ubuntu-24 ~#
本地调用的判断
- 上述过程是本地调用。在这个
halo.py脚本中,函数t_random在本地的Python环境中被调用,所有的操作(包括导入random模块和生成随机数)都在本地计算机的Python解释器中执行,没有涉及跨网络或者跨进程的远程调用。
- 上述过程是本地调用。在这个
将其改为RPC调用的基本步骤(以使用XML - RPC为例)
- 安装必要的库:
- 需要安装
xmlrpc - server和xmlrpc - client(如果是分开的库)用于创建服务器和客户端。在Python中,可以使用pip安装。假设是Python 3,在命令行中执行pip3 install xmlrpc - server xmlrpc - client。
- 需要安装
创建服务器端代码:
修改后的服务器端代码可能如下:
from xmlrpc.server import SimpleXMLRPCServer import random def t_random(): return random.randint(1, 10) server = SimpleXMLRPCServer(("0.0.0.0", 8000)) server.register_function(t_random, "t_random") print("Server is listening on port 8000...") server.serve_forever()- 这里首先创建了一个简单的XML - RPC服务器,监听本地主机(
localhost)的8000端口。然后将t_random函数注册到服务器上,并给这个函数起了一个外部可调用的名字t_random。最后启动服务器,使其一直处于监听状态。
创建客户端代码:
客户端代码如下:
import xmlrpc.client proxy = xmlrpc.client.ServerProxy("http://192.168.110.24:8000/") result = proxy.t_random() print(f"本次随机数是:{result}")- 客户端首先创建了一个
ServerProxy对象,它代表了服务器的代理。这个代理对象的参数是服务器的地址(在这个例子中是本地主机的8000端口)。然后通过这个代理对象调用服务器上注册的t_random函数,并获取返回的结果,最后打印出来。
- 安装必要的库:
请注意,以上代码只是一个简单的示例,在实际应用中,可能需要考虑更多的因素,如安全性(例如对调用进行身份验证和授权)、错误处理(如果服务器不可用或者网络出现问题)等。同时,还有其他的RPC实现方式,如gRPC等,它们有不同的特点和应用场景。
简单理解RPC与洗衣服
同样是洗衣服,一个本地洗,一个远程洗。
- 打个比方,你在家里,要洗衣服,你直接把衣服放到洗衣机,开启洗衣机开关,这就是本地过程调用。(本地过程调用)
- 远程调用就是,你不在家里,你打个电话回家里,跟妈说帮忙洗个衣服,这就是远程过程调用。
- 也就是你的一个计算任务,是远程的服务器在执行,执行完毕,告诉你结果而已。
NFS和RPC的关系
- NFS依赖RPC实现通信
- NFS(网络文件系统)是一种分布式文件系统协议,它允许用户通过网络访问远程服务器上的文件,就像访问本地文件一样。而RPC(远程过程调用)是一种通信协议,用于实现不同进程之间的通信,在NFS中起到了关键作用。
- NFS基于RPC构建其客户端 - 服务器通信机制。当客户端想要访问NFS服务器上的文件时,它会使用RPC来发送请求。例如,客户端想要读取服务器上的一个文件,它会通过RPC向服务器发送一个“读取文件”的请求。这个请求包含了诸如文件路径、读取的起始位置和长度等信息。
- RPC在这个过程中充当了一个中间层,它将NFS客户端的请求封装成适合在网络上传输的格式,并将其发送到NFS服务器。在服务器端,RPC会接收这些请求,将其解析后传递给NFS服务器进程进行处理。处理完成后,NFS服务器又会通过RPC将结果返回给客户端。
- RPC为NFS提供抽象的远程调用接口
- RPC为NFS提供了一种抽象的方式,使得客户端可以像调用本地函数一样调用远程服务器上的文件操作。从客户端的角度来看,它不需要了解NFS服务器的具体实现细节,如服务器的文件系统类型(是ext4、xfs还是其他)、服务器的操作系统等。
- 以文件读取操作为例,在本地文件系统中,当应用程序想要读取一个文件时,它会调用操作系统提供的本地文件读取函数,如
read()函数(在C语言中)。在NFS环境中,通过RPC的抽象,客户端可以以类似的方式向NFS服务器发起文件读取请求,就好像在调用一个本地的文件读取函数一样。这种抽象大大简化了分布式文件系统的使用,使得开发人员可以更方便地编写使用NFS的应用程序。
- 两者协同工作的具体流程
- 客户端发起请求:
- 当客户端应用程序(如一个文件管理器或一个需要读取远程文件的程序)需要访问NFS服务器上的文件时,它会通过NFS客户端软件(通常集成在操作系统的文件系统层)发起请求。
- 这个请求首先会被转换成NFS协议请求格式,其中包含了要执行的文件操作(如读取、写入、删除等)和相关参数(如文件路径、数据块等)。
- 然后,NFS客户端软件会将这个请求交给RPC模块进行处理。RPC模块会将NFS请求进一步封装成RPC请求,添加必要的信息,如目标服务器的地址、端口等,并通过网络发送给NFS服务器。
- 服务器处理请求:
- NFS服务器上的RPC服务会接收到客户端发送的RPC请求。它会对请求进行解析,提取出其中的NFS请求内容。
- 然后,将NFS请求传递给NFS服务器守护进程(NFSD)进行处理。NFSD会根据请求的内容调用服务器端的本地文件系统来执行实际的文件操作。例如,如果是读取文件请求,NFSD会调用本地文件系统的读取函数来获取文件内容。
- 处理完成后,NFSD会将结果(如读取的文件内容、写入操作的成功或失败状态等)返回给RPC服务。
- 结果返回客户端:
- NFS服务器上的RPC服务会将NFSD返回的结果封装成RPC响应消息,并通过网络发送回客户端。
- 客户端的RPC模块会接收到这个响应消息,进行解析,提取出其中的NFS响应内容。
- 最后,NFS客户端软件会将响应内容转换为应用程序能够理解的格式,如将读取的文件内容提供给应用程序,或者将写入操作的成功或失败状态通知应用程序。
- 客户端发起请求:
NFS工作原理(重要)
NFS的工作原理基于客户端/服务器架构,主要通过远程过程调用(RPC)机制实现,具体如下:
服务端启动与配置
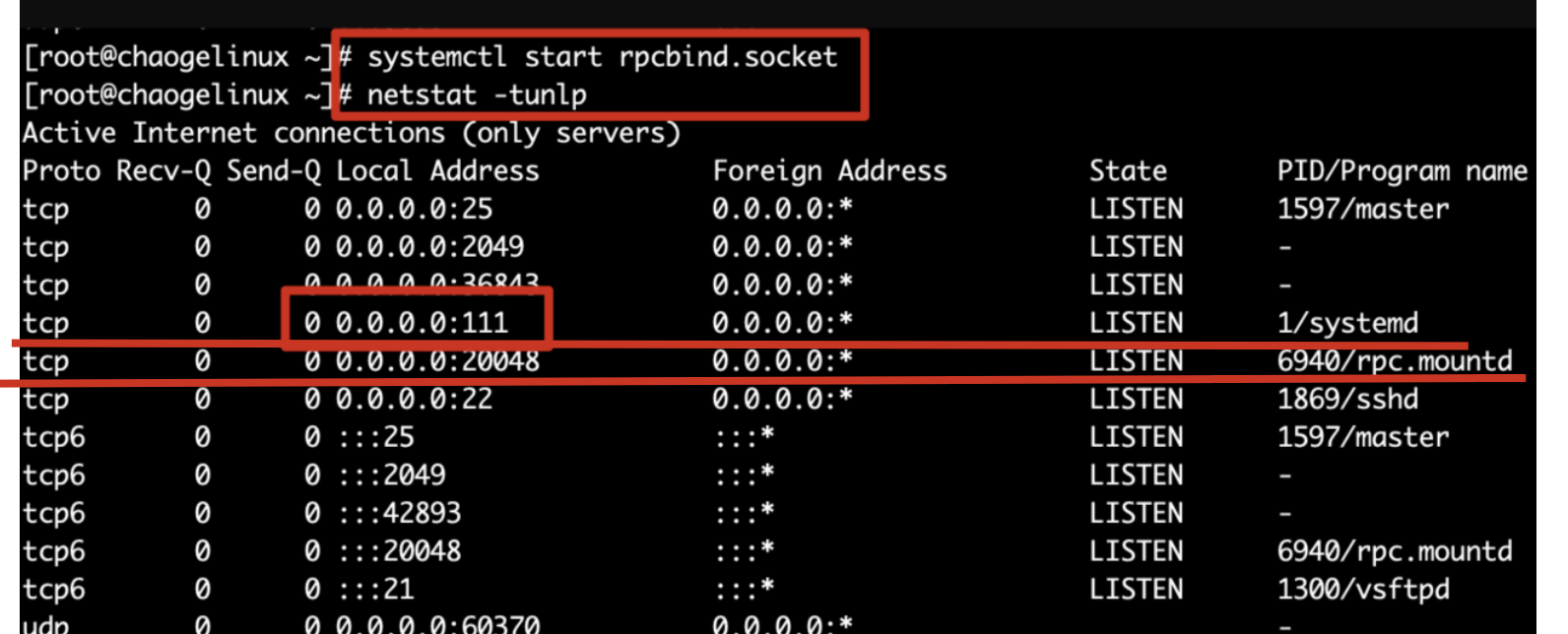
- 启动服务与注册端口:NFS服务端启动后,会将自己的端口信息注册到rpcbind服务中。rpcbind服务默认使用固定的111端口来监听客户端提交的请求,并将正确的NFS端口信息回复给客户端。
- 指定共享目录:管理员通过配置文件或相关命令指定哪些文件或目录可以被导出供其他客户端访问,例如在Linux系统中,通常会在
/etc/exports文件中进行配置。
客户端挂载与请求
- 获取端口信息:客户端通过TCP/IP协议连接到NFS服务端提供的rpcbind服务,并从该服务中获取具体的NFS服务端口信息。
- 挂载远程目录:客户端使用获取到的端口信息,向NFS服务器发送挂载请求,将远程共享目录挂载到本地文件系统中,使远程文件系统在本地可见,这个过程类似于在本地插入一个外部存储设备并进行挂载。
- 发起文件操作请求:客户端在挂载远程目录后,可以像访问本地文件系统一样对远程共享目录中的文件进行操作。当客户端需要访问服务器上的文件时,会通过RPC向服务器发送请求,如打开文件、读取文件、写入文件、关闭文件、删除文件等操作请求。
服务端处理与响应
- 权限验证:NFS服务端的rpc.nfsd进程会首先判断客户端是否有权限连接,rpc.mount进程会进一步判断客户端是否有对应的操作权限。
- 请求处理:如果客户端有相应权限,NFS服务器会将客户端请求的函数,识别为本地可以执行的命令,传递给内核,由内核驱动硬件来执行实际的文件操作,如从本地磁盘读取文件内容或向磁盘写入数据等。
- 结果返回:服务器处理完客户端的请求后,会将结果通过RPC返回给客户端。如果是文件读取请求,服务器会将读取到的文件内容返回给客户端;如果是写入请求,服务器会返回写入操作的成功或失败状态等。
数据传输与编码
- 数据传输协议:NFS使用TCP/IP协议进行数据传输,早期也采用过UDP协议。TCP协议因其可靠性高,在现代NFS应用中更为常用。
- 数据编码与转换:在数据传输过程中,NFS使用外部数据表示(XDR)协议对数据进行编码和解码。XDR可以将不同计算机、操作系统及程序语言中的数据转换成一种标准数据格式表示法,确保在异构系统之间数据的一致性和完整性,便于数据的传输和处理。
1.NFS服务端启动后、将自己的端口信息,注册到rpcbind服务中
2.NFS客户端通过TCP/IP的方式,连接到NFS服务端提供的rpcbind服务,并且从该服务中获取具体的端口信息
3.NFS客户端拿到具体端口信息后,将自己需要执行的函数,通过网络发给NFS服务端对应的端口
4.NFS服务端接收到请求后,通过rpc.nfsd进程判断该客户端是否有权限连接
5.NFS服务端的rpc.mount进程判断客户端是否有对应的操作权限
6.最终NFS服务端会将客户端请求的函数,识别为本地可以执行的命令,传递给内核、最终内核驱动硬件
结论、nfs的客户端、服务端之间的通信基于rpc协议,且必须运行rpcbind服务
rpcbind服务的作用
nfs的数据传输是通过rpc协议的。
NFS服务就是使用RPC协议的帮忙,RPC服务实现的功能是记录每个NFS功能对应的端口号,并且在NFS客户端发出请求的时候,把该功能和对应的端口信息传递给发出请求的NFS客户端,保证客户端能够正确的连接到NFS的端口,达到数据传输的目的。
RPC就好比是一个中介,处在客户端、服务端之间。
- 端口映射功能
- 原理:rpcbind服务主要起到一个端口映射的作用。在NFS(网络文件系统)以及其他基于RPC(远程过程调用)的服务环境中,服务器端会运行多个RPC服务,每个服务都有自己对应的端口。例如,NFS服务本身通常使用2049端口,但还有像mountd(用于处理挂载请求)、nfslock(用于文件锁定)等相关服务,它们的端口是动态分配的。rpcbind服务会记录这些服务的程序号(RPC程序号是一个唯一标识每个RPC服务的数字)和对应的端口号。
- 示例:当客户端想要访问NFS服务器上的文件时,它首先会联系服务器的rpcbind服务(rpcbind服务运行在固定的111端口)。客户端发送一个请求,包含它想要访问的RPC服务的程序号(比如NFS服务的程序号)。rpcbind服务收到请求后,查找自己的记录,找到对应的端口号(如NFS服务的2049端口),然后将这个端口号返回给客户端。这样,客户端就知道了应该向哪个端口发送具体的NFS服务请求。
- 服务发现机制
- 原理:rpcbind服务可以看作是一个服务发现的中心。在一个复杂的分布式系统中,可能有多个RPC服务在服务器端运行,客户端需要一种方式来找到这些服务并与之通信。rpcbind服务维护了一个服务列表,这个列表包含了服务器端所有可用的RPC服务的信息。
- 示例:假设一个服务器端同时运行了NFS、NIS(网络信息服务)等基于RPC的服务。当客户端连接到服务器的rpcbind服务时,它可以查询这个服务列表,了解到服务器端有哪些可用的服务。如果客户端需要使用NFS服务,它可以通过rpcbind获取NFS服务的端口信息;如果之后又需要使用NIS服务,同样可以从rpcbind那里获取相关的端口信息来进行通信。
- 支持异构系统通信
- 原理:在不同的操作系统和计算机体系结构之间,RPC服务的实现和端口分配可能会有所不同。rpcbind服务提供了一种标准化的方式来处理这些差异。它使用RPC协议的标准规范,使得不同系统之间能够相互理解和通信。
- 示例:在一个混合了Linux和Solaris系统的企业网络环境中,Linux系统上的NFS客户端可能需要访问Solaris系统上的NFS服务器。尽管这两个系统在底层实现上可能有差异,但通过rpcbind服务,它们可以按照RPC协议的标准方式进行端口映射和服务发现。Linux客户端可以通过Solaris服务器上的rpcbind服务获取到正确的NFS服务端口信息,从而实现跨系统的文件共享和访问。
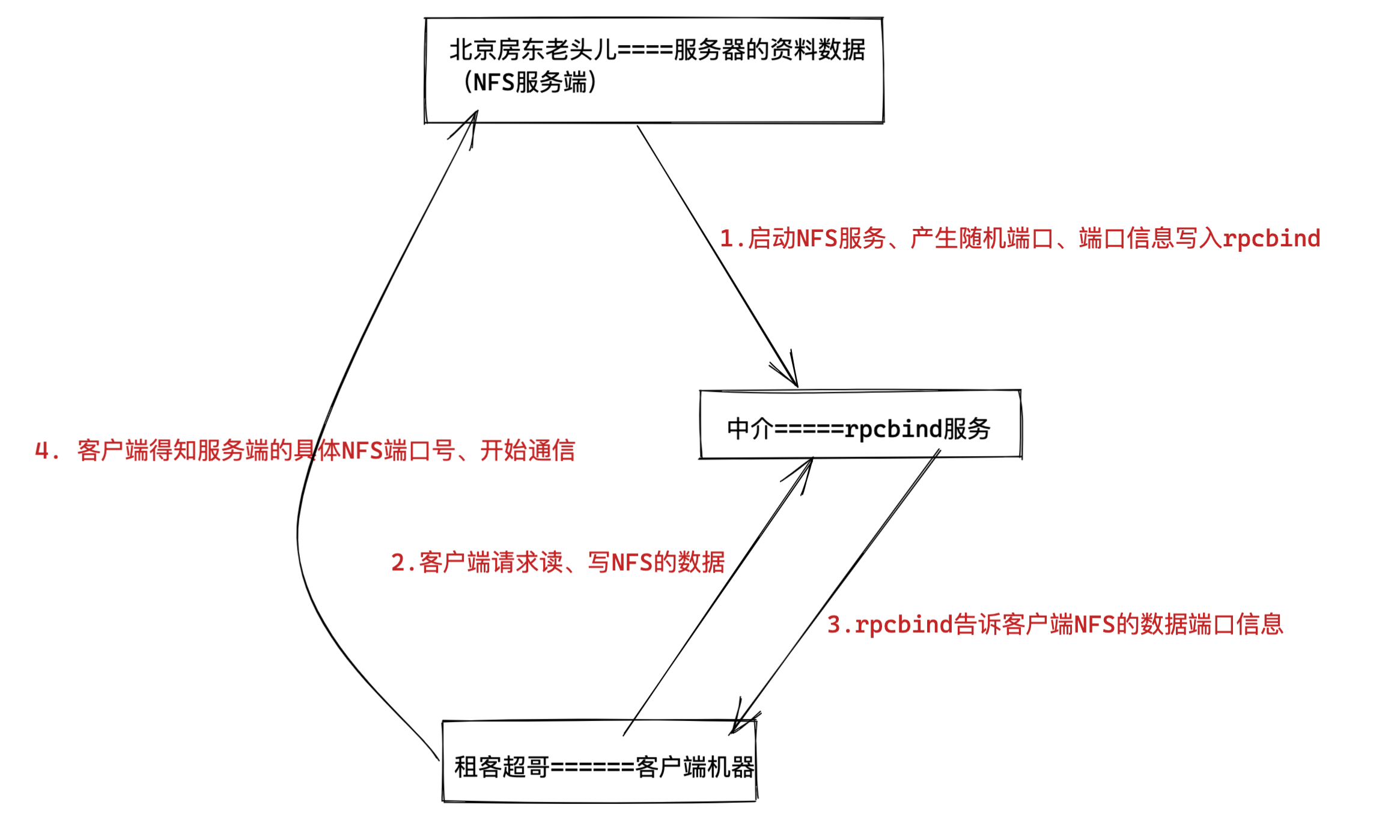
简单理解rpcbind服务
这就好比于超老师要租房,此时超哥就是一个NFS客户端
中介来介绍房子信息,中介就好比RPC服务
房源拥有者也就相当于NFS服务端,提供数据的,中介手里必须得先储备好房东的信息,才能给房源信息转达给租客。
那么RPC服务又是如何知道每个NFS的端口呢?(中介如何知道房东的具体信息呢?)
当NFS服务器启动时会随机采用若干端口,并且主动在RPC服务中注册相关端口以及功能信息。
如此一来RPC服务就知道NFS服务对应的端口功能了,RPC服务默认使用固定111端口来监听NFS客户端提交的请求,并将正确的NFS端口信息回复给NFS客户端
这样,NFS客户端就可以和NFS服务器进行数据通信了。
NFS工作流程(原理)
在启动NFS服务端之前,必须先启动RPC服务,在centos7服务器下为rpcbind服务,否则NFSserver无法向RPC注册信息了。
另外如果RPC服务重启,原来注册的NFS服务端信息也就失效了,也必须重启服务,再次注册信息给RPC服务。
特别要注意的是,修改NFS配置文件后不需要重启NFS,只需要执行exportfs -rv 命令即可或是systemctl reload nfs
图解NFS工作原理
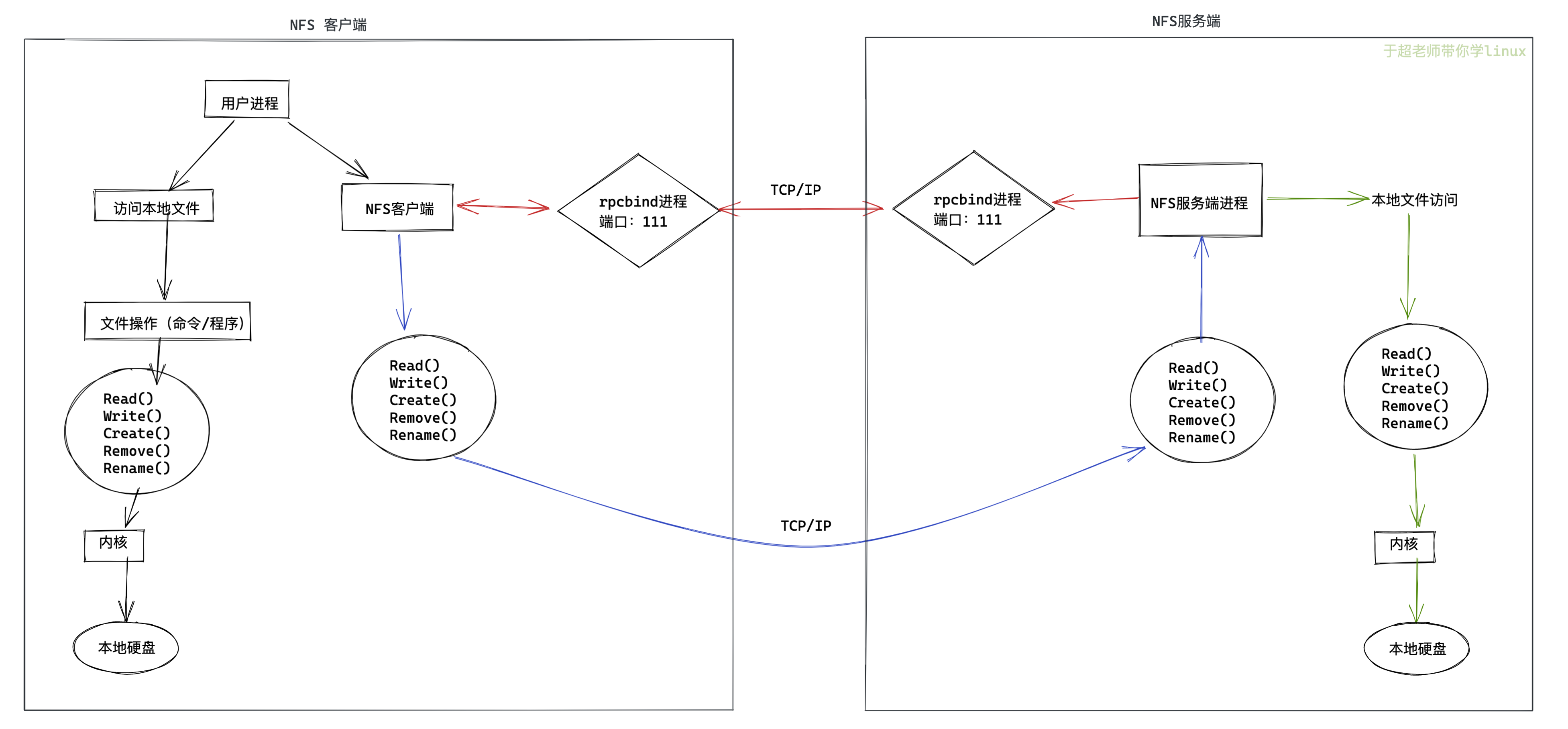
当访问程序通过NFS客户端向NFS服务器端存储文件时,其数据请求流程如下:
1.用户访问网站程序,由程序在NFS客户端上发出存取文件的请求,此时NFS客户端(执行程序的机器)的RPC服务(rpcbind)就会通过网络向NFS服务器的RPC服务的111端口发出NFS文件存取功能的请求。
2.NFS服务器RPC找到对应注册的NFS端口,通知NFS客户端RPC服务
3.此时NFS客户端获取到正确的端口,并与NFS daemon联机存取数据
4.NFS客户端把数据存取成功后返回给前端程序,告知用户存取结果,完成一次存取请求。
这也就证明,必须先启动RPC服务,再启动NFS服务的步骤。
NFS服务端配置文件理解
学习任何技术都是
1、先学技术点原理、架构流程
2、实践操作
3、部署过程如果出错,回顾原理,分析错误点。
NFS软件列表
安装nfs服务,需要安装如下软件包
- nfs-utils:NFS服务的主程序,包括了rpc.nfsd、rpc.mountd这两个守护进程以及相关文档,命令
- rpcbind:是centos7/6环境下的RPC程序
[root@yuchao-server01 ~]# rpm -qa nfs-utils rpcbind
nfs-utils-1.3.0-0.54.el7.x86_64
rpcbind-0.2.0-44.el7.x86_64
2.如果没有,需要安装nfs和rpc软件。
[root@yuchao-server01 ~]# yum install nfs-utils rpcbind -y
# ubuntu 系统
apt install nfs-kernel-server -y
环境配置
NFS也是C/S模式,准备NFS服务端,多个NFS客户端、多台linux机器。
配置文件修改
语法
默认配置文件路径是/etc/exports
exports配置文件语法
NFS共享目录 NFS客户端地址(参数1、参数2...) 客户点地址2(参数1、参数2...)
例如
/ hostname1(rw) hostname2(rw,no_root_squash)
/pub *(rw)
/home/chao 123.206.16.61(ro)
参数解释
1.NFS共享目录:为NFS服务器要共享的实际目录,必须绝对路径,注意目录的本地权限,如果要读写共享,要让本地目录可以被NFS客户端的(nfsnobody)读写
2.NFS客户端地址,也就是NFS服务器端授权可以访问共享目录的客户端地址,详见下表
3.权限参数,对授权的NFS客户端访问权限设置,见下表
nfs客户端地址说明
| 客户端地址 | 具体地址 | 说明 |
|---|---|---|
| 单一客户端 | 192.168.178.142 | 用的少 |
| 整个网段 | 192.168.178.0/24 | 24表示子网掩码255.255.255.0,指定网段,用的较多 |
| 授权域名客户端 | nfs.yuchaoit.cn | 弃用 |
| 授权整个域名客户端 | *.yuchaoit.cn | 弃用 |
示例
/home/chaoge/log 192.168.178.0/24(ro)
只读共享,例如一些生成服务器的日志目录,又不想给开发服务器的权限,可以用此办法,共享目录给他人只读查看
#修改nfs配置文件为如下示例
[root@chaogelinux nfsShare]# cat /etc/exports
/nfsShare *(insecure,rw,sync,root_squash)
#表示共享该文件夹,且提供给所有网段的机器可访问
配置规则是,可读写,数据同步写入到磁盘,把root管理员映射为本地的匿名用户,insecure是客户端从大于1024的端口发送链接
ubuntu新版nfs配置文件
root@yc-ubuntu-24 ~# cat /etc/exports
# /etc/exports: the access control list for filesystems which may be exported
# to NFS clients. See exports(5).
#
# Example for NFSv2 and NFSv3:
# /srv/homes hostname1(rw,sync,no_subtree_check) hostname2(ro,sync,no_subtree_check)
#
# Example for NFSv4:
# /srv/nfs4 gss/krb5i(rw,sync,fsid=0,crossmnt,no_subtree_check)
# /srv/nfs4/homes gss/krb5i(rw,sync,no_subtree_check)
#
/etc/exports 是一个在 Linux 系统中用于配置 NFS(Network File System,网络文件系统)共享的关键配置文件,上面的内容是该文件的注释说明:
- 开头注释:
# /etc/exports: the access control list for filesystems which may be exported:这行注释点明了/etc/exports文件的作用,即它是一个访问控制列表,用来定义哪些文件系统能够被导出(共享)给 NFS 客户端使用。# to NFS clients. See exports(5).提示用户如果想获取更详细的信息,可以查看exports命令的手册页第 5 节 ,在 Linux 系统里,使用man 5 exports就可以查看这份详细文档。
- NFSv2 和 NFSv3 示例:
# /srv/homes hostname1(rw,sync,no_subtree_check) hostname2(ro,sync,no_subtree_check):这是 NFS 版本 2 和版本 3 的共享示例。/srv/homes是要共享出去的本地目录路径。hostname1和hostname2是允许访问该共享目录的客户端主机名。针对hostname1,括号里的配置rw表示客户端对共享目录有读写(Read Write)权限,sync要求所有的更改都要同步写入磁盘后才回复客户端,no_subtree_check则是一种优化选项,用来避免一些额外的权限检查;对于hostname2,ro意味着客户端只有只读(Read Only)权限,其他sync和no_subtree_check选项作用与前面一致。
- NFSv4 示例:
# /srv/nfs4 gss/krb5i(rw,sync,fsid=0,crossmnt,no_subtree_check):这里是 NFS 版本 4 的共享示例。/srv/nfs4是共享目录,gss/krb5i涉及到使用 Kerberos 安全机制的客户端标识,rw赋予读写权限,sync保证同步写盘,fsid=0用来标识整个 NFS 服务器导出的根目录 ,crossmnt允许客户端跨挂载点访问,no_subtree_check同样是权限检查相关的优化设置。# /srv/nfs4/homes gss/krb5i(rw,sync,no_subtree_check):/srv/nfs4/homes是共享的子目录,相关权限设置和前面类似,只是没有了fsid=0和crossmnt这两个特定选项。
整体来看,这个文件现在还只是一些示例和注释内容,并没有实际生效的共享配置,需要管理员按照示例格式添加真实的共享目录、客户端主机以及对应权限等配置项。
NFS4版本
- NFSv4的基本概念
- NFSv4(Network File System version 4)是NFS协议的一个版本。它相比之前的版本(如NFSv2和NFSv3)在功能和架构上有了很多改进。NFSv4旨在提供更强大的安全性、更好的性能以及更简单的配置和管理。
- 示例中的配置参数理解
- 共享目录部分:
- 在示例
/srv/nfs4 gss/krb5i(rw,sync,fsid = 0,crossmnt,no_subtree_check)中,/srv/nfs4是NFS服务器要共享的目录路径。
- 在示例
- 客户端标识部分:
gss/krb5i是用于标识客户端的一种方式,这里涉及到使用Kerberos安全机制(GSS - API with Kerberos V,即gss/krb5i)来进行身份验证。Kerberos是一种网络认证协议,它通过使用票据(ticket)来提供安全的身份验证,以确保只有授权的客户端能够访问共享资源。
- 访问权限和其他设置部分:
rw表示客户端对共享目录有读写(Read - Write)权限,这意味着客户端可以在该共享目录下创建新文件、修改现有文件和删除文件等操作。sync要求所有的更改都要同步写入磁盘后才回复客户端。这是一种数据安全的保障机制,确保数据在磁盘上的状态和客户端看到的状态尽可能一致,减少因缓存等原因导致的数据不一致问题。fsid = 0用于在NFSv4中标识文件系统的根(File System ID)。当设置为0时,通常表示整个NFS服务器导出的根目录。这个设置在跨挂载点访问等场景中很重要,它可以帮助NFS客户端正确识别文件系统的层次结构。crossmnt是一个与挂载点相关的选项。它允许客户端跨挂载点访问,这意味着客户端可以通过一个挂载点访问到服务器上多个相关的共享目录,就好像这些目录是一个连续的文件系统一样,提供了更灵活的访问方式。no_subtree_check在前面已经解释过,它是一种优化选项,在这里表示服务器不会对共享目录的路径进行严格的子树检查,以提高性能。
- 第二个示例
/srv/nfs4/homes gss/krb5i(rw,sync,no_subtree_check):- 共享目录是
/srv/nfs4/homes,客户端标识同样是gss/krb5i,访问权限为读写(rw)、同步写入(sync),并且也采用了no_subtree_check优化选项。与第一个示例相比,这个共享目录可能是/srv/nfs4的一个子目录,并且没有fsid = 0和crossmnt这两个选项,说明它可能在文件系统层次结构中的定位和访问方式与/srv/nfs4有所不同。
- 共享目录是
- 共享目录部分:
- NFSv4的优势体现
- 安全性增强:
- 如示例中看到的通过
gss/krb5i这种基于Kerberos的身份验证机制,NFSv4能够更好地控制客户端的访问权限,防止未经授权的访问。这在企业级网络环境或者对数据安全要求较高的场景中非常重要。
- 如示例中看到的通过
- 简化的架构和配置:
- NFSv4采用了单一的统一协议,相比之前版本在配置和管理上更加简单。例如,在挂载共享目录时,NFSv4不需要像之前版本那样指定多个挂载选项来处理不同的功能,它自身的设计使得很多操作更加直观。
- 性能优化:
- 选项如
no_subtree_check和sync等的合理配置可以在保证数据安全的基础上,通过减少不必要的检查和优化写入方式来提高NFS的性能。同时,NFSv4在协议本身的设计上也对性能进行了优化,例如在文件锁定、缓存管理等方面都有改进,能够更好地适应现代网络存储的需求。
- 选项如
- 安全性增强:
no_subtree_check参数
- 基本概念
subtree_check是NFS(网络文件系统)中的一个重要选项,用于控制服务器在处理文件访问请求时的检查方式。当NFS服务器共享一个目录(比如/data),并且客户端尝试访问这个共享目录下的文件(如/data/file.txt)时,subtree_check选项就会发挥作用。
- 工作原理
- 当
subtree_check选项被启用(设置为subtree_check,这是默认情况,在旧版本的nfs - utils中),NFS服务器会检查每个文件请求的路径是否在共享目录树的范围内。例如,如果服务器共享了/home目录,客户端请求访问/home/user1/file.txt,服务器会验证/home/user1/file.txt这个路径是从共享的/home目录衍生出来的,即它是/home目录“树”的一部分。 - 这种检查是一种安全机制,它可以防止客户端通过一些巧妙的请求来访问服务器上不应该被共享的文件。例如,如果共享目录是
/home,没有这种检查,客户端可能会尝试访问/etc/passwd等非共享目录下的文件。
- 当
- 与no_subtree_check的对比
no_subtree_check是subtree_check的相反设置。当设置为no_subtree_check时,服务器不会进行这种严格的路径检查。这样做可以提高性能,因为减少了检查步骤。但是,这也可能带来一定的安全风险,因为客户端可能会利用这种宽松的设置访问到服务器上不希望被访问的文件,不过在安全的网络环境或者经过仔细规划的共享场景下,no_subtree_check可以是一个很好的性能优化选项。
- 实际应用场景示例
- 假设你有一个NFS服务器,它主要用于在公司内部共享用户的家目录(
/home)。在一个高度安全的环境中,你可能希望启用subtree_check来确保客户端只能访问共享目录及其子目录下的文件。 - 但是,如果是在一个测试环境中,例如开发团队内部共享一些临时的代码存储库,并且你对网络安全有一定的信心,为了提高NFS服务器的响应速度,你可以设置为
no_subtree_check。
- 假设你有一个NFS服务器,它主要用于在公司内部共享用户的家目录(
配置参数警告
root@yc-ubuntu-24 ~# exportfs -r
exportfs: /etc/exports [2]: Neither 'subtree_check' or 'no_subtree_check' specified for export "192.168.110.96:/nfs-data1".
Assuming default behaviour ('no_subtree_check').
NOTE: this default has changed since nfs-utils version 1.0.x
nfs服务端参数
root@yc-ubuntu-24 ~# cat /etc/exports
# /etc/exports: the access control list for filesystems which may be exported
# to NFS clients. See exports(5).
#
# Example for NFSv2 and NFSv3:
# /srv/homes hostname1(rw,sync,no_subtree_check) hostname2(ro,sync,no_subtree_check)
#
# Example for NFSv4:
# /srv/nfs4 gss/krb5i(rw,sync,fsid=0,crossmnt,no_subtree_check)
# /srv/nfs4/homes gss/krb5i(rw,sync,no_subtree_check)
#
/nfs-data1 192.168.110.96(ro,sync,no_subtree_check)
NFS客户端检查NFS服务端共享情况
sudo apt install nfs-common -y
root@ubuntu-96:~# showmount -e 192.168.110.24
Export list for 192.168.110.24:
/nfs-data1 192.168.110.96
# 挂载NFS服务端
# 挂载语法
mount -t 文件系统 远程nfs地址 本地挂载点
root@ubuntu-96:~# mount -t nfs 192.168.110.24:/nfs-data1 /my_local_nfs_dir/
root@ubuntu-96:~#
# 只读无法写入
root@ubuntu-96:~# touch /my_local_nfs_dir/到此一游.txt
touch: cannot touch '/my_local_nfs_dir/到此一游.txt': Read-only file system
root@ubuntu-96:~#
# 服务端可以写入
root@yc-ubuntu-24 ~# touch /nfs-data1/我是服务端可写.txt
root@yc-ubuntu-24 ~#
#挂载参数
root@ubuntu-96:~# mount -l |grep nfs
192.168.110.24:/nfs-data1 on /my_local_nfs_dir type nfs4 (rw,relatime,vers=4.2,rsize=1048576,wsize=1048576,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=192.168.110.96,local_lock=none,addr=192.168.110.24)
NFS挂载目录容量
root@ubuntu-96:~# df -h
Filesystem Size Used Avail Use% Mounted on
tmpfs 388M 1.6M 387M 1% /run
/dev/mapper/ubuntu--vg-ubuntu--lv 24G 14G 8.7G 62% /
tmpfs 1.9G 0 1.9G 0% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
/dev/sda2 2.0G 242M 1.6G 14% /boot
tmpfs 388M 4.0K 388M 1% /run/user/1000
192.168.110.24:/nfs-data1 49G 21G 26G 45% /my_local_nfs_dir
root@ubuntu-96:~#
- 理解NFS共享目录容量与根目录的关系
- 在你提供的信息中,
df - h命令输出的内容主要是关于本地文件系统各个挂载点的容量使用情况,并没有直接体现NFS共享目录容量与根目录的关联。 - NFS共享目录(这里是
/nfs - data1共享给192.168.110.96)的容量是独立于本地根目录(/,对应的设备是/dev/sda3)容量来统计的。
- 在你提供的信息中,
- NFS共享目录容量的确定
- NFS共享目录的容量大小是由NFS服务器在共享该目录时所设定的存储大小决定的。从
df - h的输出中没有直接找到NFS共享目录容量与本地根目录的参照关系。 - 例如,在
df - h输出中有一个挂载点192.168.110.24:/nfs - data1 49G 21G 26G 45% /my_local_nfs_dir(你之前提供过类似内容),这里的49G是NFS服务器端共享的/nfs - data1目录的总大小,它和本地根目录(/dev/sda3)的49G没有必然的关联,是分别独立的存储资源统计。
- NFS共享目录的容量大小是由NFS服务器在共享该目录时所设定的存储大小决定的。从
- NFS共享目录挂载后的使用情况
- 当NFS共享目录挂载到本地(如
/my_local_nfs_dir)后,其已用空间(Used)、可用空间(Avail)和使用率(Use%)是基于NFS服务器端共享目录本身的存储来计算的,和本地根目录的使用情况也是相互独立的。这可以帮助用户分别管理本地存储和NFS共享存储的资源。
- 当NFS共享目录挂载到本地(如
NFS客户端挂载参数
root@ubuntu-96:~#
root@ubuntu-96:~# mount -l |grep nfs
192.168.110.24:/nfs-data1 on /my_local_nfs_dir type nfs4 (rw,relatime,vers=4.2,rsize=1048576,wsize=1048576,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=192.168.110.96,local_lock=none,addr=192.168.110.24)
/etc/exports文件内容解释- 文件整体作用:
/etc/exports文件用于配置NFS(Network File System)服务器的共享目录和访问权限。它定义了哪些目录可以被共享给哪些客户端,以及客户端对这些共享目录的访问权限等相关设置。
- 文件中的注释部分:
- 开头的几行注释说明了文件的用途,即这是一个用于控制文件系统导出(共享)给NFS客户端的访问控制列表。并且提示用户可以查看
exports(5)手册页获取更详细的信息。 - 随后分别给出了NFSv2和NFSv3、NFSv4的共享示例,包括共享目录路径、允许访问的客户端主机名(或客户端标识)以及一系列的访问权限和其他设置选项。这些示例主要是为了帮助管理员理解如何正确配置共享目录。
- 开头的几行注释说明了文件的用途,即这是一个用于控制文件系统导出(共享)给NFS客户端的访问控制列表。并且提示用户可以查看
- 实际配置部分:
/nfs - data1 192.168.110.96(ro,sync,no_subtree_check)这一行是实际的NFS共享配置。/nfs - data1是NFS服务器(在yc - ubuntu - 24这台主机上)要共享的本地目录路径。192.168.110.96是被允许访问该共享目录的客户端IP地址。ro表示客户端(ubuntu - 96)对这个共享目录只有只读(Read - Only)权限,这意味着客户端不能对这个共享目录进行写操作,如创建新文件、修改现有文件或删除文件等。sync表示所有的更改(虽然这里是只读权限,但如果有元数据的更改等情况)都要同步写入磁盘后才回复客户端。这是一种数据安全的保障机制,确保数据在磁盘上的状态和客户端看到的状态尽可能一致。no_subtree_check在前面已经解释过,它是一种优化选项,在这里表示服务器不会对共享目录的路径进行严格的子树检查,以提高性能。
- 文件整体作用:
mount - l | grep nfs命令输出解释- 命令作用:
mount - l用于列出当前系统中所有已挂载的文件系统及其相关信息。grep nfs是对输出结果进行过滤,只显示和NFS相关的挂载信息。
- 输出内容解释:
192.168.110.24:/nfs - data1 on /my_local_nfs_dir type nfs4这部分表示NFS共享目录的挂载情况。192.168.110.24:/nfs - data1是NFS共享源,即从IP地址为192.168.110.24(NFS服务器)的/nfs - data1目录进行共享。/my_local_nfs_dir是本地系统(ubuntu - 96)上挂载NFS共享目录的挂载点路径。这意味着在本地系统的/my_local_nfs_dir目录下可以访问到来自NFS服务器的/nfs - data1目录中的内容。type nfs4表示挂载的文件系统类型是NFS版本4。- 后面括号内的内容是一系列挂载选项,例如:
rw这里似乎和/etc/exports文件中的ro权限冲突,不过实际上这个rw可能是挂载时的默认尝试设置或者是其他因素导致的显示。但真正的读写权限还是以/etc/exports文件中的ro为准,即客户端应该是只读访问。relatime是一种文件系统时间戳更新策略,它使得文件的访问时间(atime)只有在文件的修改时间(mtime)或者文件状态改变时间(ctime)更新之后才会更新,这样可以减少磁盘I/O操作。vers = 4.2明确了挂载的NFS版本是4.2,这与前面的type nfs4相呼应,并且给出了更详细的版本信息。rsize = 1048576和wsize = 1048576分别表示NFS读块大小和写块大小,单位是字节,这里设置为1048576字节(1MB),这些参数用于优化NFS数据传输的性能。namlen = 255规定了文件名长度的最大值为255个字符。hard是一种挂载选项,当NFS服务器出现故障或者网络问题时,使用hard挂载的客户端会一直尝试重新连接,直到恢复通信。proto = tcp表示NFS通信使用TCP协议,这是一种可靠的传输协议,有助于保证数据传输的稳定性。timeo = 600设置了NFS客户端等待服务器响应的超时时间为600个单位(通常是十分之一秒),即60秒。retrans = 2表示在超时后,客户端会尝试重新传输的次数为2次。sec = sys表示使用系统默认的安全机制,通常是基于用户ID和组ID来进行身份验证。clientaddr = 192.168.110.96再次明确了客户端的IP地址。local_lock = none表示本地不使用文件锁,这可能是因为NFS本身有自己的锁机制或者在这种情况下不需要本地锁。addr = 192.168.110.24明确了NFS服务器的IP地址。
- 命令作用:
nfs排错(权限不足)
#错误问题
root@ubuntu-96:~# cd /my_local_nfs_dir/
root@ubuntu-96:/my_local_nfs_dir# ll
total 8
drwxr-xr-x 2 root root 4096 Jan 6 10:44 ./
drwxr-xr-x 25 root root 4096 Jan 6 10:40 ../
-rw-r--r-- 1 root root 0 Jan 6 10:21 chaoge66-nfs.log
-rw-r--r-- 1 root root 0 Jan 6 10:44 我是服务端可写.txt
root@ubuntu-96:/my_local_nfs_dir# touch 123
touch: cannot touch '123': Permission denied
# 排查思路1,检查服务端
root@yc-ubuntu-24 ~# tail -1 /etc/exports
/nfs-data1 192.168.110.96(rw,sync,no_subtree_check)
# 检查客户端
root@ubuntu-96:/# umount /my_local_nfs_dir
mount -t nfs -o rw 192.168.110.24:/nfs-data1 /my_local_nfs_dir/
root@ubuntu-96:/# mount -l |grep nfs
192.168.110.24:/nfs-data1 on /my_local_nfs_dir type nfs4 (rw,relatime,vers=4.2,rsize=1048576,wsize=1048576,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=192.168.110.96,local_lock=none,addr=192.168.110.24)
root@ubuntu-96:/#
# 客户端看到的nfs服务端容量
root@ubuntu-96:/# df -hT |grep nfs
192.168.110.24:/nfs-data1 nfs4 49G 21G 26G 45% /my_local_nfs_dir
# 执行用户的权限问题
# 因为,存在root_seuqash参数把客户端的root,映射为了nobody用户,导致没有w权限,无法操作。
root@yc-ubuntu-24 /# cat /etc/exports
# /etc/exports: the access control list for filesystems which may be exported
# to NFS clients. See exports(5).
#
# Example for NFSv2 and NFSv3:
# /srv/homes hostname1(rw,sync,no_subtree_check) hostname2(ro,sync,no_subtree_check)
#
# Example for NFSv4:
# /srv/nfs4 gss/krb5i(rw,sync,fsid=0,crossmnt,no_subtree_check)
# /srv/nfs4/homes gss/krb5i(rw,sync,no_subtree_check)
#
/nfs-data1 192.168.110.96(rw,sync,no_subtree_check,no_root_squash)
root@yc-ubuntu-24 /#
# 不做身份映射,直接以nfs服务端上的root操作即可,内网下nFS放开了用。
推荐NFS权限做法
在生产环境中配置NFS挂载时,确保写入权限安全、稳定、可控非常重要。以下是推荐的生产环境配置方案:
1. 确保目录权限安全配置
导出目录权限: 在NFS服务器上,将导出目录的权限限制为特定用户和组(而不是给全体用户开放写权限,如
777),例如:chown nobody:nogroup /nfs-data1/ chmod 770 /nfs-data1 # 后续,只有root操作,会被映射被nobody,才可以读写该目录这样,只有特定用户和组才能访问该目录。
使用ACL(访问控制列表): 如果需要更细粒度的权限控制,可以使用
setfacl设置ACL权限:setfacl -m u:nfsuser:rwx /nfs-data1 setfacl -m g:nfsgroup:rwx /nfs-data1
2. 合理配置 /etc/exports 文件
在生产环境中,应根据实际需求配置NFS导出选项:
最小化客户端范围:仅允许需要访问的客户端IP地址。
/nfs-data1 192.168.110.96(rw,sync,no_subtree_check)或使用子网限制:
/nfs-data1 192.168.110.0/24(rw,sync,no_subtree_check) 允许 192.168.110.0 ~ 192.168.110.255之间的地址访问该NFS使用
no_root_squash慎重:- 默认情况下,NFS将客户端的
root用户映射为nobody用户(root_squash),避免服务器被恶意操作。 - 在生产环境中,尽量避免使用
no_root_squash,如果必须使用,请将导出目录限制为特定客户端。
- 默认情况下,NFS将客户端的
推荐选项说明:
/nfs-data1 192.168.110.96(rw,sync,no_subtree_check,secure)rw:允许读写操作。sync:数据写入操作同步完成,保证数据一致性。no_subtree_check:提高性能并减少权限问题。secure:仅允许从1024以下的端口发起的NFS请求。
3. 启用 NFSv4 并配置身份验证
使用NFSv4:
- NFSv4引入了更好的性能和安全性,是生产环境的推荐版本。
- 配置示例:
/nfs-data1 192.168.110.96(rw,sync,no_subtree_check,fsid=0)
Kerberos身份验证: 配置NFS与Kerberos集成,通过GSSAPI(通用安全服务API)实现用户认证、数据完整性校验、数据加密等功能:
- 修改
/etc/exports文件:/nfs-data1 192.168.110.96(rw,sync,sec=krb5i)sec=krb5:仅身份验证。sec=krb5i:身份验证并提供数据完整性校验。sec=krb5p:身份验证并对数据进行加密。
- 修改
4. 客户端挂载优化
在客户端,挂载NFS共享目录时使用以下推荐选项:
mount -o rw,relatime,vers=4.2,rsize=1048576,wsize=1048576,hard,timeo=600,retrans=2 192.168.110.24:/nfs-data1 /mnt/nfs-data1
rw:读写挂载。relatime:减少文件元数据更新时间,提升性能。vers=4.2:指定使用NFSv4.2。rsize和wsize:设置读写块大小,优化传输性能。hard:强制客户端重试挂载,避免数据丢失。timeo和retrans:设置超时和重试次数。
5. 网络安全与隔离
- 隔离NFS流量:通过专用网络(如VLAN)或独立存储网络(如iSCSI专用子网)传输NFS流量。
- 防火墙限制:仅允许NFS相关端口(如
2049)在服务器和客户端之间通信。 - 加密通道:在必要时使用VPN或IPSec加密NFS流量。
6. 日志与监控
- 在NFS服务器上启用详细日志记录,定期审计:
exportfs -v - 配置系统监控工具(如Prometheus或Zabbix)监控NFS的性能和可用性。
总结
生产环境推荐:
- 使用严格的文件系统权限和ACL控制访问。
- 最小化NFS导出范围,避免使用
no_root_squash。 - 启用NFSv4并结合Kerberos身份验证。
- 优化客户端挂载参数以提升性能。
- 加强网络隔离与安全防护,确保传输加密和访问控制。
配置文件参考
配置文件格式:
/nfs-yuchao-nginx 172.16.1.0/24(rw,sync,all_squash,anonuid=1000,anongid=1000)
共享目录 允许客户端访问的IP (挂载参数、NFS共享参数)
注意,限制访问的网段和(挂载参数)之间没有空格
NFS配置文件参数解释
ro 只读
rw 读写
root_squash 当nfs客户端以root访问时,它的权限映射为NFS服务端的匿名用户,它的用户ID/GID会变成nfsnobody
no_root_squash 同上,但映射客户端的root为服务器的root,不安全,避免使用
all_squash 所有nfs客户端用户映射为匿名用户,生产常用参数,降低用户权限,增大安全性。
sync 数据同步写入到内存与硬盘,优点数据安全,缺点性能较差
async 数据写入到内存,再写入硬盘,效率高,但可能内存数据会丢
/etc/exports man 5 exports
共享目录 共享选项
/nfs/share *(ro,sync)
共享主机:
* :代表所有主机
192.168.0.0/24:代表共享给某个网段
192.168.0.0/24(rw) 192.168.1.0/24(ro) :代表共享给不同网段
192.168.0.254:共享给某个IP
*.yuchaoit.cn:代表共享给某个域下的所有主机
共享选项:
ro:只读,不常用
rw:读写
sync:实时同步,直接写入磁盘
async:异步,先缓存在内存再同步磁盘
anonuid:设置访问nfs服务的用户的uid,uid需要在/etc/passwd中存在
anongid:设置访问nfs服务的用户的gid
root_squash :默认选项 root用户创建的文件的属主和属组都变成nfsnobody,其他人nfs-server端是它自己,client端是nobody。
no_root_squash:root用户创建的文件属主和属组还是root,其他人server端是它自己uid,client端是nobody。
all_squash: 不管是root还是其他普通用户创建的文件的属主和属组都是nfsnobody
说明:
anonuid和anongid参数和all_squash一起使用。
all_squash表示不管是root还是其他普通用户从客户端所创建的文件在服务器端的拥有者和所属组都是nfsnobody;服务端为了对文件做相应管理,可以设置anonuid和anongid进而指定文件的拥有者和所属组
root_squash参数
root_squash选项的存在性- Ubuntu的NFS(Network File System)是有
root_squash选项的。root_squash是NFS共享配置中的一个重要安全设置。
- Ubuntu的NFS(Network File System)是有
root_squash的作用- 当NFS服务器设置了
root_squash(这是默认行为)时,来自客户端的以root用户(用户ID为0)发起的访问请求会被映射为服务器上的一个非特权用户(通常是nobody或nfsnobody)。 - 例如,如果没有
root_squash,客户端的root用户在访问NFS共享目录时,在服务器端也会以root权限进行操作,这可能会带来安全风险,因为客户端的root用户可能会误操作或者恶意修改服务器端共享目录中的重要文件。 - 当
root_squash生效时,客户端的root用户就被“压制”,只能以较低权限用户的身份在服务器端的共享目录中进行操作,从而增强了系统的安全性。
- 当NFS服务器设置了
- 在
/etc/exports文件中的配置方式- 在Ubuntu的
/etc/exports文件中,可以像这样配置root_squash选项。假设要共享/data目录给192.168.1.100这个客户端:/data 192.168.1.100(rw,root_squash)。这表示共享/data目录给指定客户端,客户端有读写权限(rw),并且启用了root_squash选项。
- 还有一个相反的选项是
no_root_squash,如果使用/data 192.168.1.100(rw,no_root_squash)这样的配置,客户端的root用户在访问共享目录时就不会被映射为非特权用户,而是保留root权限。不过,这种配置通常在安全要求不高或者经过特殊信任的环境下才会使用,因为它可能会带来安全隐患。
- 在Ubuntu的
NFS服务端部署实践(重要)

1.安装软件
[root@nfs-31 ~]#yum install nfs-utils rpcbind -y
2.启动、检查rpcbind进程
[root@nfs-31 ~]#netstat -tunlp |grep rpc
[root@nfs-31 ~]#systemctl status rpcbind
[root@nfs-31 ~]#systemctl start rpcbind
[root@nfs-31 ~]#netstat -tunlp |grep rpc
3. 创建nfs配置文件
all_squash: 不管是root还是其他普通用户创建的文件的属主和属组都是nfsnobody
rw 允许读写
sync 数据同步到磁盘
cat > /etc/exports <<EOF
/nfs-yuchao-nginx 172.16.1.0/24(rw,sync,all_squash)
EOF
4.创建NFS共享文件夹(设置权限,给nfs默认的匿名用户,降低权限,保护系统安全)
[root@nfs-31 ~]#mkdir -p /nfs-yuchao-nginx
[root@nfs-31 ~]#chown -R nfsnobody.nfsnobody /nfs-yuchao-nginx/
5.启动NFS服务
systemctl start nfs
6.检查nfs服务状态、以及端口、以及进程信息
[root@nfs-31 ~]#systemctl status nfs
[root@nfs-31 ~]#netstat -tnlp|grep rpc
[root@nfs-31 ~]#ps -ef|grep nfs
7.检查nfs服务端的共享情况,使用showmount命令查看
[root@nfs-31 ~]#showmount -e 172.16.1.31
Export list for 172.16.1.31:
/nfs-yuchao-nginx 172.16.1.0/24
8.查看nfs服务端远程共享的所有参数,是系统自动生成的,以及我们配置文件里定义的,都是默认的不需要了解太多
[root@nfs-31 ~]#cat /var/lib/nfs/etab
/nfs-yuchao-nginx 172.16.1.0/24(rw,sync,wdelay,hide,nocrossmnt,secure,root_squash,all_squash,no_subtree_check,secure_locks,acl,no_pnfs,anonuid=65534,anongid=65534,sec=sys,rw,secure,root_squash,all_squash)
9.设置nfs服务端开机自启、包括rpncbind服务
[root@nfs-31 ~]#systemctl is-enabled nfs
disabled
[root@nfs-31 ~]#systemctl enable rpcbind nfs
Created symlink from /etc/systemd/system/multi-user.target.wants/nfs-server.service to /usr/lib/systemd/system/nfs-server.service.
注意:
/etc/exports文件的语法不要写错,细心
修改/etc/exports文件后,注意要重启systemctl reload nfs或是exportfs -r重新加载配置,无需重启
NFS客户端部署实践(重要)
1.安装nfs工具包
[root@web-7 ~]#yum install nfs-utils -y
2.运行客户端的rpcbind程序
[root@web-7 ~]#systemctl start rpcbind
[root@web-7 ~]#netstat -tnlp|grep rpc
tcp 0 0 0.0.0.0:111 0.0.0.0:* LISTEN 4412/rpcbind
tcp6 0 0 :::111 :::* LISTEN 4412/rpcbind
3.远程查看nfs服务器信息
[root@web-7 ~]#showmount -e 172.16.1.31
Export list for 172.16.1.31:
/nfs-yuchao-nginx 172.16.1.0/24
4.挂载测试
[root@web-7 ~]#mkdir -p /data
[root@web-7 ~]#mount -t nfs 172.16.1.31:/nfs-yuchao-nginx /data
[root@web-7 ~]#df -h|grep nfs
172.16.1.31:/nfs-yuchao-nginx 17G 1.8G 16G 11% /data
5.测试写入数据
[root@web-7 /data]#mkdir 超哥带你学nfs
[root@web-7 /data]#touch 超哥带你学nfs/牛啊牛啊.log
[root@web-7 /data]#
[root@web-7 /data]#tree -NF
.
└── 超哥带你学nfs/
└── 牛啊牛啊.log
1 directory, 1 file
[root@web-7 /data]#
[root@web-7 /data]#ll
total 0
drwxr-xr-x 2 nfsnobody nfsnobody 30 Apr 20 17:29 超哥带你学nfs
[root@web-7 /data]#ll 超哥带你学nfs/
total 0
-rw-r--r-- 1 nfsnobody nfsnobody 0 Apr 20 17:29 牛啊牛啊.log
6.配置开机自动挂载nfs
[root@web-7 /data]#tail -1 /etc/fstab
172.16.1.31:/nfs-yuchao-nginx /data nfs defaults 0 0
7.测试开启自动挂载nfs
[root@web-7 ~]#umount /data
[root@web-7 ~]#
[root@web-7 ~]#df -h |grep nfs
[root@web-7 ~]#
[root@web-7 ~]#mount -a
[root@web-7 ~]#df -h |grep nfs
172.16.1.31:/nfs-yuchao-nginx 17G 1.8G 16G 11% /data
[root@web-7 ~]#ls /data
超哥带你学nfs
NFS挂载参数实践
ro只读挂载
设置只读共享文件夹,并且限制可访问的机器(现有一批培训文档,提供给员工只读查看)
1.修改nfs配置文件
root@nfs-31 /nfs-yuchao-nginx]#systemctl reload nfs
[root@nfs-31 /nfs-yuchao-nginx]#cat /etc/exports
/nfs-yuchao-nginx 172.16.1.0/24(rw,sync,all_squash)
/data2 172.16.1.41(ro,sync,all_squash)
[root@nfs-31 /nfs-yuchao-nginx]#
[root@nfs-31 /nfs-yuchao-nginx]#showmount -e 172.16.1.31
Export list for 172.16.1.31:
/nfs-yuchao-nginx 172.16.1.0/24
/data2 172.16.1.41
2.创建测试数据 /data2
[root@nfs-31 /nfs-yuchao-nginx]#mkdir -p /data2/培训文档/
[root@nfs-31 /nfs-yuchao-nginx]#
[root@nfs-31 /nfs-yuchao-nginx]#touch /data2/培训文档/年底优秀员工名单.txt
[root@nfs-31 /nfs-yuchao-nginx]#chown -R nfsnobody:nfsnobody /data2
3.使用客户端验证该共享目录
(使用web-7机器验证)
[root@web-7 ~]#mount -t nfs 172.16.1.31:/data2 /t2
mount.nfs: mounting 172.16.1.31:/data2 failed, reason given by server: No such file or directory
(使用rsync-41机器验证),注意nfs客户端,得安装nfs相关工具包,否则报错,无法挂载nfs类型文件系统
yum install nfs-utils -y
[root@rsync-41 ~]#mount -t nfs 172.16.1.31:/data2 /d2
[root@rsync-41 ~]#df -h |grep d2
172.16.1.31:/data2 17G 1.8G 16G 11% /d2
[root@rsync-41 ~]#
[root@rsync-41 ~]#ls /d2
培训文档
[root@rsync-41 ~]#ls /d2/培训文档/年底优秀员工名单.txt -l
-rw-r--r-- 1 nfsnobody nfsnobody 0 Apr 20 17:38 /d2/培训文档/年底优秀员工名单.txt
[root@rsync-41 ~]#
[root@rsync-41 ~]#cd /d2
[root@rsync-41 /d2]#touch 我也是优秀员工好吗.log
touch: cannot touch ‘我也是优秀员工好吗.log’: Read-only file system
验证all_squash,anonuid,anongid权限
说明:
anonuid和anongid参数和all_squash一起使用。
all_squash表示不管是root还是其他普通用户从客户端所创建的文件在服务器端的拥有者和所属组都是nfsnobody;服务端为了对文件做相应管理,可以设置anonuid和anongid进而指定文件的拥有者和所属组
anonuid:设置访问nfs服务的用户的uid,uid需要在/etc/passwd中存在
anongid:设置访问nfs服务的用户的gid
all_squash: 不管是root还是其他普通用户创建的文件的属主和属组都是nfsnobody
修改nfs共享目录创建的文件属性,为指定用户www
服务端操作
1.修改nfs配置文件
[root@nfs-31 ~]#cat /etc/exports
/nfs-yuchao-nginx 172.16.1.0/24(rw,sync,all_squash)
/data2 172.16.1.41(ro,sync,all_squash)
/data3 172.16.1.0/24(rw,sync,all_squash,anonuid=1000,anongid=1000)
2.创建新的共享目录,以及权限设置
[root@nfs-31 ~]#useradd www -u 1000 -M -s /sbin/nologin
[root@nfs-31 ~]#mkdir /data3
[root@nfs-31 ~]#chown -R www.www /data3
[root@nfs-31 ~]#touch /data3/测试anonuid.log
3.让nfs加载新配置,或者systemctl reload nfs
[root@nfs-31 ~]#exportfs -r
客户端操作
1.查看nfs服务端共享情况
[root@web-7 ~]#showmount -e 172.16.1.31
Export list for 172.16.1.31:
/data3 172.16.1.0/24
/nfs-yuchao-nginx 172.16.1.0/24
/data2 172.16.1.41
2.挂载nfs
[root@web-7 ~]#mount -t nfs 172.16.1.31:/data3 /t3
[root@web-7 ~]#
[root@web-7 ~]#df -h |grep t3
172.16.1.31:/data3 17G 1.8G 16G 11% /t3
3.写入数据,查看权限
[root@web-7 /t3]#touch 我的老天鹅啊.log
[root@web-7 /t3]#ll
total 0
-rw-r--r-- 1 www www 0 Apr 20 17:53 hehe
-rw-r--r-- 1 www www 0 Apr 20 17:56 我的老天鹅啊.log
-rw-r--r-- 1 www www 0 Apr 20 17:49 测试anonuid.log
注意用户管理权限篇的理解,user、group、other的 rwx权限
课间练习
要求使用机器
nfs-31 nfs服务端
web-7 nfs客户端
rsync-41 nfs客户端
三台机器
1.在nfs服务端创建两个共享目录,权限如下
/ops_data 权限是可读写
/dev_data 权限只读
2.通过两个nfs客户端挂载、读写测试
NFS故障案例
1.nfs服务端崩溃
服务端关闭nfs
当nfs服务端崩溃后,客户端nfs会卡死
[root@nfs-31 /data3]#systemctl stop nfs
nfs客户端查看挂载情况
对该挂载目录的操作全部卡死
[root@web-7 /t3]#ls
^C
[root@web-7 /t3]#df -h
^C
也无法取消挂载
[root@web-7 ~]#umount /t3
^C
解决办法
1.修复nfs服务端
服务端
[root@nfs-31 /data3]#systemctl start nfs
客户端
[root@web-7 ~]#ls /t3
hehe 师傅你是干什么的.log 我的老天鹅啊.log 测试anonuid.log
2.强制卸载客户端的nfs挂载
[root@web-7 ~]#umount --help
-f, --force force unmount (in case of an unreachable NFS system)
-l, --lazy detach the filesystem now, and cleanup all later
取消客户端所有对该nfs服务端的挂载即可
[root@web-7 ~]#umount -lf /t3
[root@web-7 ~]#umount -lf /data
df命令恢复了
[root@web-7 ~]#df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/centos-root 17G 1.6G 16G 10% /
devtmpfs 980M 0 980M 0% /dev
tmpfs 992M 0 992M 0% /dev/shm
tmpfs 992M 9.6M 982M 1% /run
tmpfs 992M 0 992M 0% /sys/fs/cgroup
/dev/sda1 1014M 130M 885M 13% /boot
tmpfs 199M 0 199M 0% /run/user/0
2.nfs服务端崩溃导致重启服务器卡死
1.如果nfs客户端设置了/etc/fstab开机自启,重启服务器后会导致无法正确挂载nfs服务端,卡死无法启动,解决办法就是等待1分钟30秒左右会自动正确自动
2.进入单用户模式,紧急模式,修复/etc/fstab文件,重启即可
nfs与nginx实战
上面给的任务是,nginx的网站数据,并非来自于nginx服务器本地,而是nfs共享服务器的数据,部署方案如下
nfs-31机器操作
[root@nfs-31 /nfs-yuchao-nginx]#systemctl start nfs
[root@nfs-31 /nfs-yuchao-nginx]#cat index.html
<meta charset=utf-8>
于超老师带你学nfs+nginx
web-7机器操作
1.安装nginx软件,必须配置好epel源
[root@web-7 ~]#yum install nginx -y
2.查看nginx网页目录的默认文件,默认的本地数据
[root@web-7 ~]#ls /usr/share/nginx/html/
404.html 50x.html en-US icons img index.html nginx-logo.png poweredby.png
3.现在该nginx软件,要读取来自于nfs共享存储的数据
[root@web-7 ~]#mount -t nfs 172.16.1.31:/nfs-yuchao-nginx /usr/share/nginx/html/
[root@web-7 ~]#df -h |grep nginx
172.16.1.31:/nfs-yuchao-nginx 17G 1.8G 16G 11% /usr/share/nginx/html
4.启动nginx客户端,访问页面
systemctl start nginx
5.本地测试nginx访问
[root@web-7 ~]#curl 127.0.0.1
<meta charset=utf-8>
于超老师带你学nfs+nginx
6.使用elink命令访问
[root@web-7 ~]#yum install elinks -y
[root@web-7 ~]#elinks 172.16.1.7
7.使用客户端访问
http://10.0.0.7/
如果nfs服务端挂了会如何?
拿不到数据,页面卡死,需要需求nfs,或者依然是强制取消挂载
1.systemctl start nfs
2.[root@web-7 ~]#umount -lf /usr/share/nginx/html
重启nginx即可
总结NFS
1.NFS 存储优点
1.NFS 文件系统简单易用、方便部署、数据可靠、服务稳定、满足中小企业需求。
2.NFS 存储局限
1.存在单点故障, 如果构建高可用维护麻烦 web->nfs->backup
2.NFS 数据明文, 并不对数据做任何校验。
3.客户端挂载 NFS 服务没有密码验证, 安全性一般(内网使用),除非借助第三方软件辅助认证功能。
3.NFS 应用建议
1.生产场景应将静态数据尽可能往前端推, 减少后端存储压力
2.必须将存储里的静态资源通过 CDN 缓存 jpg\png\mp4\avi\css\js
再多内容,以后慢慢学,还有如阿里云提供的NAS云存储,也是使用到了NFS功能
https://www.aliyun.com/product/nas