12-Ansible-playbook剧本
ansible临时命令ad-hoc
ansible中有两种模式,分别是ad-hoc模式和playbook模式
ad-hoc简而言之,就是"临时命令"
https://docs.ansible.com/ansible/latest/user_guide/intro_adhoc.html
临时命令非常适合您很少重复的任务。例如,如果您想在圣诞节假期关闭实验室中的所有机器。
Ansible ad hoc 命令使用/usr/bin/ansible命令行工具在一个或多个托管节点上自动执行单个任务。ad hoc 命令既快速又简单,但它们不可重复使用。
ansible-playbook
Ansible Playbooks 提供了一个可重复、可重用、简单的配置管理和多机部署系统,非常适合部署复杂的应用程序。
# 一键部署nfs+nginx的剧本,redhat和debian判断
如果您需要多次使用 Ansible 执行任务,请编写剧本并将其置于源代码控制之下。
ansible-playbook 是 Ansible 自动化工具中的一个核心命令,用于执行使用 YAML 格式编写的剧本(Playbook)。
剧本是一系列有序任务的集合,通过 ansible-playbook 可以让 Ansible 按照剧本中的定义在多个目标主机上执行复杂的自动化任务,如系统配置、软件部署、服务管理等。以下从多个方面详细解释 ansible-playbook:
- 给什么机器执行?
- 执行什么任务?说什么,做什么
- 期望什么结果
基本语法
ansible-playbook [选项] 剧本文件.yml
- 选项:可以控制
ansible-playbook的行为,例如指定主机清单文件、设置 SSH 用户、调整并发度等。 - 剧本文件.yml:包含自动化任务定义的 YAML 文件。
常用选项
| 选项 | 作用 |
|---|---|
-i <主机清单文件> |
指定主机清单文件,默认为 /etc/ansible/hosts。 |
-u <用户名> |
指定 SSH 连接使用的用户名。 |
-k |
提示输入 SSH 密码。 |
--ask-become-pass |
提示输入 sudo 密码(用于提升权限)。 |
-f <并发数> |
设置并行处理的主机数量,提高执行效率。 |
-v |
增加输出的详细程度,最多可使用 4 个 v(-vvvv)用于调试。 |
--list-hosts |
列出剧本将在哪些主机上执行,而不实际执行任务。 |
--syntax-check |
检查剧本文件的语法是否正确,不执行任务。 |
剧本文件结构
一个典型的 Ansible 剧本由多个 “play” 组成,每个 “play” 定义了一组目标主机和要在这些主机上执行的任务。以下是一个简单的剧本示例:
---
- name: 卸载 Nginx
hosts: web
become: true # 使用 sudo 权限执行任务
tasks:
- name: 卸载 Nginx
apt:
name: nginx
state: absent
- name: 关闭 Nginx 服务
service:
name: nginx
state: stopped
enabled: no
name:“play” 的名称,用于描述该 “play” 的作用。hosts:指定目标主机或主机组。become:是否使用sudo权限执行任务。tasks:包含一系列要执行的任务,每个任务有一个名称和使用的模块及参数。
执行过程
当运行 ansible-playbook 命令时,Ansible 会按以下步骤执行:
- 解析剧本文件:检查剧本文件的语法是否正确,确保可以正常解析。
- 连接目标主机:根据主机清单文件和指定的连接信息(如 SSH 用户、密码等),尝试与目标主机建立 SSH 连接。
- 收集主机信息(可选):默认情况下,Ansible 会使用
setup模块收集目标主机的系统信息(facts),这些信息可在剧本中作为变量使用。 - 执行任务:按照剧本中定义的顺序,依次在目标主机上执行每个任务。每个任务执行完成后,会返回执行结果(如成功、失败、变更等)。
- 输出结果:将任务的执行结果输出到控制台,显示每个任务在各个目标主机上的执行状态和详细信息。
示例命令
以下是一些常见的 ansible-playbook 命令示例:
- 执行
nginx_setup.yml剧本,使用默认主机清单文件:ansible-playbook nginx_setup.yml - 执行
app_deploy.yml剧本,指定主机清单文件和 SSH 用户:ansible-playbook -i /path/to/inventory app_deploy.yml -u myuser - 执行
database_config.yml剧本,提示输入sudo密码并增加输出详细程度:ansible-playbook database_config.yml --ask-become-pass -vv
优点
- 可重复性:剧本文件可以多次执行,确保在不同环境中实现一致的自动化操作。
- 可维护性:剧本使用 YAML 格式编写,结构清晰,易于阅读和修改。
- 扩展性:可以通过添加更多的 “play” 和任务,实现复杂的自动化流程。
总之,ansible-playbook 是 Ansible 实现自动化运维的重要工具,通过编写和执行剧本,可以高效地管理和配置大量的目标主机。
yaml,非常重要,ansible掌握好,docker,k8s,以后所有高级配置,yaml语法居多。
多个play语法
在 Ansible 中,ansible - playbook 可以通过在 YAML 文件里定义多个 play 来完成不同的任务组合,每个 play 都可以有自己的目标主机、任务、变量等。下面为你详细介绍如何定义多个 play 以及给出示例代码。
基本结构
一个包含多个 play 的 Ansible Playbook 文件基本结构如下:
- name: 第一个 play 的名称
hosts: 目标主机组或主机名
tasks:
- name: 任务 1 的名称
模块名:
参数: 值
- name: 任务 2 的名称
模块名:
参数: 值
- name: 第二个 play 的名称
hosts: 目标主机组或主机名
tasks:
- name: 任务 3 的名称
模块名:
参数: 值
- name: 任务 4 的名称
模块名:
参数: 值
示例代码
以下是一个包含两个 play 的 Ansible Playbook 示例,第一个 play 用于在目标主机上创建一个目录,第二个 play 用于在该目录下创建一个文件。
# 第一个 play:创建目录
- name: 创建目录
hosts: web # 假设目标主机组名为 web_servers
#become: true # 使用 root 权限执行任务
tasks:
- name: 创建目录 /data/app
file:
path: /data/app
state: directory
mode: '0755'
# 第二个 play:创建文件
- name: 创建文件
hosts: nfs_server
become: true
tasks:
- name: 先创建文件夹 /nfs_data
file:
path: /nfs_data
state: directory
mode: "0755"
- name: 在 /data/app 目录下创建文件 test.txt
copy:
content: "This is a test file,By yuchao...\n"
dest: /nfs_data/test.txt
mode: '0644'
ansible nfs_server -m file -a 'path=/nfs_data state=directory mode="0755"'
ansible web -m copy -a 'content="This is a test file,By yuchao...\n" dest="/data/app/test.txt" mode="0644" '
执行 Playbook
将上述代码保存为一个 YAML 文件,例如 multi_play.yml,然后使用以下命令执行该 Playbook:
ansible-playbook multi_play.yml
代码解释
第一个
play:name:该play的名称为 “创建目录”。hosts:指定目标主机组为web_servers。become: true:表示使用root权限执行任务。tasks:包含一个任务,使用file模块在目标主机上创建/data/app目录,并设置权限为0755。
第二个
play:name:该play的名称为 “创建文件”。hosts:同样指定目标主机组为web_servers。become: true:使用root权限执行任务。tasks:包含一个任务,使用copy模块在/data/app目录下创建test.txt文件,并写入指定内容,设置权限为0644。
通过这种方式,你可以在一个 Ansible Playbook 文件中定义多个 play,实现更复杂的自动化任务。
多个剧本合并
在 Ansible 里,你可以使用 --- 来分隔多个 YAML 文档,把多个不同功能的 YAML 片段合并在一个文件中,每个 YAML 文档都可以当作一个独立的 play。以下是详细的介绍和示例。
原理说明
在 YAML 格式中,--- 用于分隔不同的文档。在 Ansible Playbook 里,你可以把每个 play 视为一个独立的 YAML 文档,通过 --- 分隔后,这些 play 就可以组合在同一个文件里,由 ansible - playbook 命令依次执行。
示例代码
假设你有三个不同功能的 play,分别用于安装软件包、创建文件和启动服务,以下是合并后的示例:
Install_nginx.yml
change_html.yml
start_html.yml
ansible-playbook
# 第一个 play:安装 Nginx 软件包
- name: 安装 Nginx
hosts: web
become: true
tasks:
- name: 安装 Nginx
apt:
name: nginx
state: latest
when: ansible_os_family == "Debian"
- name: 安装 Nginx
yum:
name: nginx
state: present
when: ansible_os_family == "RedHat"
# 第二个 play:创建测试文件
- name: 创建测试文件
hosts: web
become: true
tasks:
- name: 创建文件 /var/www/html/test.html
copy:
content: "<html><body><h1>Hello, World!By www.yuchaoit.cn </h1></body></html>"
dest: /var/www/html/index.html
mode: '0644'
# 第三个 play:启动 Nginx 服务
- name: 启动 Nginx 服务
hosts: web
become: true
tasks:
- name: 启动 Nginx 服务
service:
name: nginx
state: started
enabled: true
执行 Playbook
把上述代码保存为一个文件,例如 combined_playbook.yml,然后使用以下命令执行:
ansible-playbook combined_playbook.yml
代码解释
第一个
play:- 此
play的作用是在web_servers主机组上安装 Nginx 软件包。 - 根据目标主机的操作系统家族(
Debian或RedHat),分别使用apt或yum模块进行安装。
- 此
第二个
play:- 该
play会在web_servers主机组上的/var/www/html目录下创建一个名为test.html的文件,并写入简单的 HTML 内容。
- 该
第三个
play:- 这个
play用于启动web_servers主机组上的 Nginx 服务,并设置为开机自启。
- 这个
通过使用 --- 分隔不同的 play,你可以将多个功能组合在一个文件中,方便管理和执行复杂的自动化任务。
---三个杠解读
在 Ansible Playbook 中,--- 是 YAML 文档分隔符,用于定义 YAML 文件中的多文档结构。以下是它的核心作用和用法:
1. --- 的核心作用
- 分隔多个 YAML 文档: 允许在一个 YAML 文件中编写多个独立的文档(例如:多个 Play、变量文件、任务列表)。
- 提升可读性: 显式标记文档的起始位置,尤其在复杂 Playbook 中更清晰。
语法层面没问题,可知ansible新版,已经隐式的去掉了---的写法,无需手动分割。
否则它会认为,文档出现断层。
不要加就好了。
剧本语法
既然要写剧本,就得按照剧本的格式去编写
【比如一个电影剧本】

电影名
演员
场景
时间
事件
台词
道具
ansible剧本,一系列的任务,按照我们期望的结果编排在一起
hosts: 定义主机角色
tasks: 具体执行的任务
例如,于超老师的快乐生活
- 节目名字: 于超的快乐生活
演员列表: 于超,alex
场景:
- 场景1: 于超老师开始授课linux
动作1: 头戴麦克风,手拿机械键盘,一顿噼里啪啦疯狂输出
- 场景2: alex老师开始授课python
动作1: 一顿狮吼功,震耳欲聋,讲过的爬虫程序如同蝗虫过境,没讲一次课,就有一个网站崩溃
对比playbook的语法
- hosts: 需要执行的机器,nfs
tasks:
- 任务1:安装nfs
动作: yum install nfs
- 任务2:创建数据目录
动作: mkdir -p xxxx
剧本优势
1.减少重复性的书写命令,例如你在上一节重复性敲打了N次命令
ansible backup -m shell -a "echo 超哥牛逼"
2.剧本更加简洁,容易阅读
3.功能更强大,书写更专业,支持条件判断、循环、变量、标签
4.剧本也就是脚本,可以发到任意机器上,部署任意复杂的程序
5.ansible提供了对剧本语法检查,以及模拟执行
yaml语法
YAML(YAML Ain't Markup Language)是一种人类可读的数据序列化格式,常用于配置文件和数据交换。
在 Ansible 中,Playbook 就是使用 YAML 语法编写的。以下是 YAML 语法的详细介绍:
基本规则
- 大小写敏感:YAML 是大小写敏感的,例如
Name和name被视为不同的键。 - 使用缩进表示层级关系:通过缩进表示数据的嵌套结构,一般使用空格进行缩进,不建议使用制表符。同一层级的元素缩进必须一致。
- 注释:以
#开头的行是注释,会被解析器忽略。
数据类型
1. 标量(Scalars)
- 字符串:可以使用单引号或双引号括起来,也可以不使用引号。如果字符串中包含特殊字符,建议使用引号。
# 不使用引号 name: John Doe # 使用单引号 city: 'New York' # 使用双引号 message: "Hello, World!" - 数字:可以是整数或浮点数。
age: 30 price: 9.99 - 布尔值:使用
true或false表示布尔值。is_active: true - 空值:使用
null或~表示空值。phone: null
2. 列表(Lists)
列表使用 - 表示元素,多个元素依次排列。
fruits:
- Apple
- Banana
- Orange
也可以使用紧凑格式:
fruits: [Apple, Banana, Orange]
3. 字典(Dictionaries)
字典由键值对组成,键和值之间用冒号分隔。
person:
name: John Doe
age: 30
city: New York
也可以使用紧凑格式:
person: {name: John Doe, age: 30, city: New York}
嵌套结构
YAML 支持列表和字典的嵌套,通过缩进表示层级关系。
employees:
- name: John Doe
age: 30
department: Sales
- name: Jane Smith
age: 25
department: Marketing
引用和别名
可以使用 & 定义别名,使用 * 引用别名,实现数据的复用。
defaults: &defaults
user: admin
password: secret
development:
<<: *defaults
host: dev.example.com
production:
<<: *defaults
host: prod.example.com
在上面的例子中,&defaults 定义了一个别名,<<: *defaults 引用了这个别名,将 defaults 中的键值对合并到 development 和 production 中。
多行字符串
可以使用 | 或 > 来表示多行字符串。
|:保留换行符。description: | This is a multi-line description. It preserves line breaks.>:折叠换行符,将多行合并为一行。summary: > This is a summary that spans multiple lines. But it will be merged into one line.
锚点和引用
使用锚点(&)和引用(*)可以在 YAML 文件中复用数据。
user: &user_info
name: John
age: 30
another_user:
<<: *user_info
location: New York
在这个例子中,&user_info 创建了一个锚点,*user_info 引用了这个锚点,将 user 的键值对合并到 another_user 中。
在 Ansible 中的应用
在 Ansible Playbook 中,YAML 用于定义任务、主机、变量等。以下是一个简单的 Ansible Playbook 示例:
ansible 输出结果,可以直接选择,导出为json,网络交换数据格式。
---
- name: Install and start Nginx
hosts: webservers
become: true
tasks:
- name: Install Nginx
apt:
name: nginx
state: present
- name: Start Nginx service
service:
name: nginx
state: started
enabled: yes
这个 Playbook 定义了一个任务,用于在 webservers 主机组上安装并启动 Nginx 服务。
手写yaml,看看你会多少了
# 手写json,试试,用yaml表示,怎么写
{
"2025":{
"任务": [
"学linux、sre",
"学Python,做devops运维研发",
"学aiops,跟上大趋势"
]
}
}
在线json转换yaml
https://www.dute.org/yaml#google_vignette
学习yaml技巧
写完yaml,不确定缩进关系对不对,去在线yaml网站,格式化,判断语法是否正常。
- yaml本身有缩进语法,空格表示缩进(空格数量无所谓,对齐,即表示并列的关系)
- yaml本身有数据类型,字符串,数字,浮点数,布尔值,列表,字典
- yaml最好是和json对应理解
- yaml 剧本,docker yaml文件
yaml特点
1.严格的缩进(空格数)表示层级关系(一般敲2个空格表示一个层级关系)
2.不要使用tab键
3.冒号: 后面一定得有空格
4.短横线- 后面一定得有空格
5.剧本文件名必须是yaml或者yml,程序可以读取,以及vim提供颜色高亮
案例
https://github.com/robcowart/docker_compose_cookbook/blob/master/nginx/docker-compose.yml
语法强化,yaml,json转化理解
手写json的数据结构,转化得到这个yaml
yaml数据类型,理解。
version: '3'
services:
nginx:
image: nginx:1.17.3
container_name: nginx
restart: unless-stopped
hostname: nginx
network_mode: bridge
ports:
- 80:80/tcp
- 443:443/tcp
volumes:
- /etc/nginx:/etc/nginx
#environment:
思考过程
YAML是JSON的超集,也就是说,YAML可以被转换成JSON结构。用户提供的YAML文件看起来是一个典型的Docker Compose配置,里面定义了一个nginx服务。
首先,我需要确定转换的基本规则。YAML使用缩进和符号来表示结构,而JSON使用大括号和方括号,并且需要双引号包裹键名和字符串值。因此,转换时需要注意结构对应,比如YAML的键值对要变成JSON的键值对,列表要转换为数组。
接下来,看用户提供的YAML结构。最外层是version和services两个键。version的值是'3',而services下有一个nginx服务,里面包含多个配置项,比如image、container_name等。每个配置项可能需要对应到JSON的相应位置。
首先处理顶层结构。version对应JSON中的键,其值是字符串"3"。services是一个对象,里面包含各个服务,这里只有nginx一个服务。所以services在JSON中应该是一个对象,键是"nginx",值是该服务的配置对象。
然后看nginx服务的各个属性。image的值是'nginx:1.17.3',转换成JSON时应该用双引号。container_name是nginx,同样字符串处理。restart的值是unless-stopped,hostname是nginx,network_mode是bridge,这些都是字符串。
ports部分是一个列表,包含两个字符串元素。YAML中的列表在JSON中变成数组。每个端口映射是字符串,如'80:80/tcp',转成JSON时直接作为数组元素,注意引号。
volumes也是一个列表,每个元素是字符串,对应到JSON数组中的元素。例如,'/etc/nginx:/etc/nginx'作为数组项。
需要注意的是,YAML中的布尔值或数字可能需要转换,但在这个例子中所有值都是字符串,所以直接处理即可。此外,YAML中的键如version、services等在JSON中也应该用双引号包裹。
接下来,检查是否有嵌套结构。比如services下的nginx服务是一个对象,包含多个键值对。在JSON中,这些键值对需要正确嵌套在对应的结构中。
还有一个需要注意的是,YAML中的某些键可能对应到Docker Compose特定的配置,但在转换为JSON时不需要特别处理,只需保持结构一致即可。例如,network_mode设置为bridge,这在JSON中直接作为字符串处理。
总结一下步骤:
确定顶层结构,version和services。
将services中的每个服务转换为JSON对象,键为服务名(如nginx),值为包含其配置的对象。
将每个服务的属性逐一转换,处理字符串、列表等结构。
确保所有键都用双引号,字符串值也用双引号,列表转换为数组。
检查缩进和结构是否正确,避免语法错误。
现在,我需要将这个过程转化为具体的JSON结构。例如,version对应顶层的一个键,services包含一个nginx对象,该对象内部有image、container_name等属性。ports和volumes都是数组,元素是字符串。
可能需要注意的细节是,YAML中的端口映射如'80:80/tcp'在JSON中是否要拆分成对象还是保持字符串。根据Docker Compose的规范,端口映射通常以字符串形式表示,所以保持原样即可。
最后,组装整个JSON结构,确保格式正确,没有遗漏任何键或值,并且语法正确,比如逗号的使用和大括号的闭合。
手写json转换思路
将 Docker Compose YAML 转换为 JSON 的思路和步骤:
转换逻辑:
- YAML 的键值对直接对应 JSON 的键值对,需要写
{} - YAML 列表转换为 JSON 数组,
[] - 嵌套结构保持层级对应
- 字符串值需要加
双引号 - 保持 Docker Compose 的结构逻辑
手工转换后的 JSON:
{
"version": "3",
"services": {
"nginx": {
"image": "nginx:1.17.3",
"container_name": "nginx",
"restart": "unless-stopped",
"hostname": "nginx",
"network_mode": "bridge",
"ports": [
"80:80/tcp",
"443:443/tcp"
],
"volumes": [
"/etc/nginx:/etc/nginx"
]
}
}
}
详细转换步骤说明:
顶层结构处理:
version直接对应顶层属性services作为包含所有服务的父对象
服务定义处理:
- 服务名称
nginx作为 services 对象的 key - 服务属性按层级转换为嵌套对象:
nginx: image: ... → "nginx": { "image": ... }
- 服务名称
数据类型转换:
- 所有字符串值添加双引号(原 YAML 的引号可去除)
- 列表结构转为数组:
ports: - '80:80/tcp' → "ports": ["80:80/tcp"]
特殊值处理:
unless-stopped保持字符串形式bridge网络模式直接转换- 端口映射保持 HOST:CONTAINER 格式
保持结构等价性:
- 映射关系完全保留
- 顺序无关(JSON 对象无序)
- 注释无法保留(原 YAML 没有注释)
注意事项:
- JSON 需要严格的双引号
- 不支持 YAML 的锚点引用等高级特性
- 布尔值需要特别注意(本例中没有)
- 数值类型会自动识别(本例中都是字符串)
- 空值需要用
null表示
如果需要反向转换(JSON → YAML),反向应用这些规则即可,同时注意:
- 去除冗余引号
- 使用缩进代替大括号
- 用短横线
-表示数组项 - 恢复合适的字符串格式(如不需要引号的纯字符串)
安装nginx的示例对比
ad-hoc命令模式
[root@m01 ~]# ansible web -m yum -a "name=nginx state=absent"
[root@m01 ~]# ansible web -m shell -a "rpm -qa nginx warn=false"
转变为playbook写法。。。
playbook模式
- 语法的对齐,不得多一个少一个空格
- 输入法保证英文
[root@m01 scripts]# cat nginx.yaml -n
1 # install nginx yaml ,by chaoge
2 - hosts: all
3 tasks:
4 - name: Install nginx Package
5 yum: name=nginx state=present
6 - name: Copy Nginx.conf
7 copy: src=./nginx.conf dest=/etc/nginx/nginx.conf mode=0644
转变为ad-hoc命令模式写法。。。
root@ansible-01:~/ansible_shell# cat t1.yml
- name: test yaml
hosts: web
tasks:
- name: xxx
apt:
name: nginx
state: present
#apt: name=nginx state=present
解释如上的playbook代码,按行解释
1.表示注释信息,可以用#,也可以用 --- 三个短横线
2.定义playbook管理的目标主机,all表示所有的主机,也可以写 主机组名
3.定义playbok所有的任务集合信息,比如该文件,定义了2个任务 ,安装nginx,拷贝nginx配置文件
4.定义了任务的名词,自定义的帮助信息
5.定义任务的具体操作,比如这里用yum模块实现nginx的安装
6.注释信息
7.第六、第七两行作用是使用copy模块,把本地当前的nginx.conf配置文件,分发给其他所有客户端机器,且授权
通过如上的剧本解读,各位兄弟姐妹们应该已经有了点感觉,其实编写剧本并不是特别复杂的事。我们需要注意如下两点:
- 剧本内容组成规范
- 剧本语法规范
playbook组成规范
hosts: 需要执行的机器
tasks: 需要执行的任务
name: 任务名称
刚才说了,剧本就像演员演戏,导演提供的文字资料,因此剧本重要的就是定义演员的信息,演员的任务
而Ansible的剧本也是由最基本的两个部分组成
- hosts定义剧本管理的主机信息(演员有哪些)
- tasks定义被管理的主机需要执行的任务动作(演员需要做什么事)
Ansible Playbook 是用 YAML 格式编写的,用于定义和执行一系列有序的自动化任务。下面详细介绍 Playbook 的组成规范。
整体结构
一个完整的 Ansible Playbook 通常由多个 “play” 组成,每个 “play” 是针对特定主机组执行的一组任务集合。其基本结构如下:
- name: 第一个 play 的名称
hosts: 目标主机或主机组
gather_facts: 是否收集主机信息
become: 是否使用特权执行任务
vars:
- 定义变量
- 变量1
- 变量2
- 变量3
tasks:
- 任务列表
- 任务列表2
- 任务列表3
handlers:
- 处理器列表
- name: 第二个 play 的名称
hosts: 另一组目标主机或主机组
# 其他部分...
下面对每个部分进行详细解释。
1. Play 头部信息
name
- 作用:为每个 “play” 提供一个描述性的名称,方便识别和理解该 “play” 的用途。
- 示例: ```yaml
- name: 安装并配置 Nginx 服务器 ... ```
hosts
- 作用:指定该 “play” 要执行任务的目标主机或主机组。可以使用主机名、IP 地址、主机组名,也支持通配符和逻辑运算符。
- 示例: ```yaml
- name: ... hosts: webservers # 目标为主机组 webservers ```
gather_facts
- 作用:控制是否收集目标主机的系统信息(facts)。默认值为
yes,收集的信息可在任务中作为变量使用。 - 示例: ```yaml
- name: ... hosts: ... gather_facts: yes # 收集主机信息 ```
become
- 作用:决定是否使用特权(如
sudo)执行任务。设置为true或yes时,Ansible 会尝试提升权限。 - 示例: ```yaml
- name: ... hosts: ... become: true # 使用特权执行任务 ```
2. vars 部分
作用
用于定义在当前 “play” 中使用的变量。这些变量可以在任务、模板等地方引用,提高 Playbook 的灵活性和可维护性。
示例
- name: ...
hosts: ...
vars:
app_port: 8080
db_name: mydatabase
tasks:
- name: 启动应用
command: ./app start --port {{ app_port }}
3. tasks 部分
作用
包含一系列要在目标主机上执行的任务。每个任务由名称、使用的模块和模块参数组成。
示例
- name: 安装并配置 Nginx 服务器
hosts: webservers
tasks:
- name: 安装 Nginx
apt:
name: nginx
state: present
- name: 复制 Nginx 配置文件
copy:
src: /local/path/nginx.conf
dest: /etc/nginx/nginx.conf
- name: 启动 Nginx 服务
service:
name: nginx
state: started
enabled: yes
4. handlers 部分
作用
用于定义一些特殊的任务,这些任务只有在其他任务的执行结果标记为 “changed” 时才会被触发执行。通常用于处理服务的重启、重新加载配置等操作。
示例
- name: 安装并配置 Nginx 服务器
hosts: webservers
tasks:
- name: 复制 Nginx 配置文件
copy:
src: /local/path/nginx.conf
dest: /etc/nginx/nginx.conf
notify: 重启 Nginx 服务
handlers:
- name: 重启 Nginx 服务
service:
name: nginx
state: restarted
在这个示例中,当 复制 Nginx 配置文件 任务的执行结果为 “changed” 时,会触发 handlers 中名为 重启 Nginx 服务 的任务。
其他可选部分
pre_tasks 和 post_tasks
pre_tasks:在tasks部分之前执行的任务,通常用于执行一些前置操作,如环境检查等。post_tasks:在tasks部分之后执行的任务,可用于执行一些后续清理或验证操作。
roles
- 作用:用于组织和复用代码,将相关的任务、变量、模板等封装成一个角色。可以在 “play” 中引用角色来简化 Playbook 的编写。
- 示例: ```yaml
- name: 使用角色部署应用
hosts: app_servers
roles:
- app_deployment ```
综上所述,遵循这些组成规范可以编写出结构清晰、易于维护的 Ansible Playbook。
剧本的hosts部分
定义剧本管理主机信息有一个重要的前提,就是被管理的主机,必须在Ansible主机清单文件中定义
也就是默认的/etc/ansible/hosts,否则剧本无法直接管理对应主机。
定义剧本的hosts部分,可以有如下多种方式,常见的有
# 方式一:定义所管理的主机IP地址
- hosts: 192.168.178.111
tasks:
动作...
# 方式二:定义所管理主机的名字
- hosts: backup01
tasks:
动作...
# 方式三:定义管理主机
- hosts: 192.168.178.111, rsync01
tasks:
动作...
# 方式四:管理所有主机
- hosts: all
tasks:
动作...
其实就和你直接敲打ad-hoc模式一样,前提都是主机清单文件中定义好了
ansible 172.16.1.7 -m shell -a "echo 于超老师带你学linux"
ansible nfs -m shell -a "echo 于超老师带你学linux"
ansible web -m shell -a "echo 于超老师带你学linux"
剧本的tasks部分
其实就等于你敲打的ad-hoc命令模式
1.你准备敲打多少条命令
如三条,也就是三个tasks任务,转变为
ansible web -m shell -a 'echo 超哥牛逼'
ansible web -m yum -a 'name=https state=running'
ansible web -m copy -a 'src=/etc/ansible/hosts dest=/etc/ansible/hosts owner=root group=root mode=0644 '
# 对应yaml
tasks:
- name: xxxx
shell: echo 超哥牛逼
- name: ooo
apt: name=https state=running
- name: ddd
copy: src=/etc/ansible/hosts dest=/etc/ansible/hosts owner=root group=root mode=0644
转变为yaml写法如下
具体模块的参数,如何在yaml中填写,语法有2个
- 变量形式定义task任务
- 字典形式定义任务
# 方式一:采用变量格式设置任务
tasks:
- name: make sure apache is running
service: name=https state=running
# 当传入的参数列表过长时,可以将其分割到多行
tasks:
- name: copy ansible inventory(清单) file to client
copy: src=/etc/ansible/hosts dest=/etc/ansible/hosts
owner=root group=root mode=0644
# 方式二:采用字典格式设置多任务
tasks:
- name: copy ansible inventory file to client
copy:
src: /etc/ansible/hosts
dest: /etc/ansible/hosts
owner: root
group: root
mode: 0644
yaml语法
在学习saltstack过程中,第一要点就是States编写技巧,简称SLS文件。
这个文件遵循YAML语法。初学者看这玩意很容易懵逼,来,于超老师拯救你学习YAML语法
json xml yaml 数据序列化格式
yaml容易被解析,应用于配置文件
salt的配置文件是yaml配置文件,不能用tab
saltstack,k8s,ansible都用的yaml格式配置文件
语法规则
大小写敏感
使用缩进表示层级关系
缩进时禁止tab键,只能空格
缩进的空格数不重要,相同层级的元素左侧对其即可
# 表示注释行
yaml支持的数据结构
对象: 键值对,也称作映射 mapping 哈希hashes 字典 dict 冒号表示 key: value key冒号后必须有
数组: 一组按次序排列的值,又称为序列sequence 列表list 短横线 - list1
纯量: 单个不可再分的值
对象:键值对
yaml
first_key:
second_key: second_value
python
{
'first_key':{
'second_key':'second_value',
}
}
1.安装且运行nginx的palybook示例
练习,自己写一个简单的yaml,安装,启动nginx
---
- hosts: 172.16.1.41
remote_user: root
tasks:
- name: install nginx
yum:
name: nginx
state: installed
update_cache: yes
- name: start nginx
systemd: name=nginx state=started
再写一个停止、删除nginx的yaml
---
- hosts: 172.16.1.41
remote_user: root
tasks:
- name: stop nginx
systemd: name=nginx state=stopped
- name: remove nginx
yum:
name: nginx
state: removed
通过该示例,学习yaml语法格式
---
- hosts: 10.0.0.7,10.0.0.8,10.0.0.9
remote_user: root
pre_tasks:
- name: set epel repo for Centos 7
yum_repository:
name: epel7
description: epel7 on CentOS 7
baseurl: http://mirrors.aliyun.com/epel/7/$basearch/
gpgcheck: no
enabled: True
tasks:
# install nginx and run it
- name: install nginx
yum: name=nginx state=installed update_cache=yes
- name: start nginx
service: name=nginx state=started
post_tasks:
- shell: echo "deploy nginx over"
register: ok_var
- debug: msg="{{ ok_var.stdout }}"
解读yaml
1.yaml以 --- 开头,表示这是一个yaml文件
2. yaml使用# 表示注释符号
3. yaml中的字符串一般不加引号,除非需要引用变量时候
Yaml列表
使用"- "(减号加一个或多个空格)作为列表项,也就是json中的数组。
yaml的列表在playbook中极重要,必须得搞清楚它的写法。
例如高中一班,有男同学,女同学之分
男同学的成员成为一列
女同学的成员成为一列
【yaml数据结构如下】
"男同学":
- 张三
- alex
- 于超
"女同学":
- 花花
- 月月
- 兔兔
列表数据用一个短横杠+空格组成
在playbook中,列表是定义一个局部环境,名字可有可无,表示定义一个范围,范围内的属性都属于该列表。
---
- name: list1 # 列表1,同时给了个名称
hosts: 10.0.0.7 # 指出了hosts是列表1的一个对象
remote_user: root # 列表1的属性
tasks: # 还是列表1的属性
- hosts: 10.0.0.7 # 列表2,但是没有为列表命名,而是直入主题
remote_user: root
sudo: yes
tasks:
要注意的是每一个playbook都必须包含hosts、tasks选项,也就是你剧本,至少得有
- hosts、某个人、某个机器
- tasks、这人要做什么、这机器要做什么
Yaml字典
字典是一个大众读法,也是key: value这种形式的表示形式。
---
- 班级名: yuchaolinux666班
人数:
总数: 18
男: 17
女: 1
老师:
名字: 于超
年龄: 18
学习任务: 学习linux、python云计算技术
什么时候写列表、什么时候写字典?
在运维业务中,合理选择使用 YAML 列表和字典能够让配置文件和自动化脚本更加清晰、易于维护。下面结合常见的运维场景,详细说明何时使用列表,何时使用字典。
使用列表的场景
1. 任务执行顺序
当需要按照特定顺序执行一系列任务时,列表是合适的选择。在 Ansible Playbook 中,tasks 部分就是一个典型的列表,用于按顺序列出要执行的任务。
# Ansible Playbook 中的任务列表
- name: 部署 Web 应用
hosts: webservers
tasks:
- name: 安装依赖包
apt:
name:
- python3
- python3-pip
state: present
- name: 克隆代码仓库
git:
repo: https://github.com/your-repo/app.git
dest: /var/www/app
- name: 安装 Python 依赖
pip:
requirements: /var/www/app/requirements.txt
这里的 tasks 列表确保了任务按照安装依赖包、克隆代码仓库、安装 Python 依赖的顺序依次执行。
2. 批量操作目标
在进行批量操作时,若涉及多个目标且这些目标属于同一类型,使用列表来列举这些目标非常方便。例如,在配置防火墙规则时,需要允许多个 IP 地址访问特定端口。
# 防火墙规则配置,允许多个 IP 地址访问 80 端口
firewall_rules:
- source_ip: 192.168.1.10
port: 80
- source_ip: 192.168.1.20
port: 80
- source_ip: 192.168.1.30
port: 80
这个列表清晰地列出了多个需要允许访问的 IP 地址和对应的端口。
3. 配置多个同类型服务实例
如果需要配置多个相同类型的服务实例,如多个数据库副本、多个 Web 服务器节点等,可以使用列表来管理。
# 配置多个数据库副本
database_replicas:
- host: db1.example.com
port: 5432
- host: db2.example.com
port: 5432
- host: db3.example.com
port: 5432
这里的列表方便地管理了多个数据库副本的连接信息。
使用字典的场景
1. 存储配置参数
当需要存储一组相关的配置参数,且每个参数都有一个明确的名称时,字典是最佳选择。例如,服务器的配置信息通常使用字典来组织。
# 服务器配置信息
server_config:
hostname: webserver.example.com
ip_address: 192.168.1.100
port: 8080
max_connections: 1000
通过字典,可以方便地通过键(如 hostname、ip_address 等)来访问和修改对应的配置参数。
2. 表示映射关系
在运维中,经常需要表示一些映射关系,如将服务名称映射到其对应的端口号、将主机名映射到其对应的 IP 地址等,字典能够很好地实现这种映射。
# 服务名称到端口号的映射
service_ports:
web_server: 80
ssh_server: 22
ftp_server: 21
通过这个字典,可以快速查找每个服务对应的端口号。
3. 分层级的配置结构
当配置信息具有分层级的结构时,使用字典可以清晰地表示这种层次关系。例如,一个复杂的应用程序配置可能包含多个子配置项。
# 应用程序配置
application_config:
database:
host: db.example.com
port: 5432
username: app_user
password: secret
web_server:
port: 8080
max_threads: 50
logging:
level: INFO
file: /var/log/app.log
这个字典将应用程序的配置信息按照数据库、Web 服务器和日志记录等不同方面进行了分层组织,结构清晰,易于理解和维护。

具体到playbook中,一般虚拟性的如定义一个临时的变量数据,一般都是用
key: value形式;而实质性的如找到机器上的一个具体的文件,一般是定义为列表,如多个文件列表(文件列表每一个都是单独的个体)。
---
- hosts: 10.0.0.7 # 列表1,如下都是该列表的各种属性
remote_user: root
vars:
nginx_port: 80 # 定义变量,是虚拟性的内容,应定义为字典而非列表
mysql_port: 3306
vars_files:
- nginx_port.yml # 无法写成key/value格式,且是实体文件,因此定义为列表
tasks:
- name: test2
shell: echo /tmp/a.txt
register: hi_var # register是提取shell的返回值
- debug: var=hi_var.stdout
简单说,字典的语法,一般用于定义变量信息、或者ansible模块的参数
- hosts: chaoge
tasks:
- name: create file
file:
path: /chaoge/666.txt
state: directory
mode: 644
owner: chaoge
group: chaoge
yaml换行写
保证缩进对齐即可
---
- hosts: web
tasks:
- shell: echo 万丈高楼平地起 >> /tmp/t1.log
echo 辉煌只能靠自己 >> /tmp/t1.log
echo 超哥牛逼!! >> /tmp/t1.log
修改apt源
---
- name: Replace APT sources
hosts: web
become: yes
tasks:
- name: Backup existing sources.list
copy:
src: /etc/apt/sources.list
dest: /etc/apt/sources.list.bak
# 直接远程拷贝
remote_src: yes
- name: Copy new sources.list
copy:
src: /etc/apt/sources.list
dest: /etc/apt/sources.list
owner: root
group: root
mode: '0644'
backup: yes
- name: Update APT cache
apt:
update_cache: yes
# copy语法1
# 作业,吧如下语法1,修改剧本模式,实现apt源修改
控制节点文件 > 发给目标机器,文件分发,backup参数实现备份
root@ansible-01:~/ansible_shell# ansible web -m copy -a 'src=/etc/resolv.conf dest=/etc/resolv.conf backup=yes'
# copy语法2
直接实现远程拷贝,目标机器的本地远程拷贝
ansible web -m copy -a 'src=/opt/t_copy.txt dest=/opt/t_copy.txt.bak remote_src=yes'
json和yaml语法学习
前端网页,查询课程,发起了API请求,向后端发起hTTP请求。
https://m.luffycity.com/api/v1/course/light/
后端,django,框架处理请求(python,dict字典类型处理,解析数据,),序列化为,json,正确给响应,回复json数据
python数据类型 ,json序列化,bytes网络数据。
json特点
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,具有简洁、易于阅读和编写的特点,广泛应用于 Web 应用程序、前后端数据交互、配置文件等领域。以下从多个方面详细解释 JSON:
基本概念
JSON 是基于 JavaScript 对象字面量语法的一种数据格式,但它是独立于编程语言的,几乎所有的现代编程语言都支持 JSON 数据的解析和生成。
JSON 数据以键值对的形式组织,并且可以嵌套,能够表示简单数据类型(如字符串、数字、布尔值、空值)以及复杂的数据结构(如数组和对象)。
数据类型
1. 简单数据类型
- 字符串(String):由双引号包围的字符序列,例如
"Hello, World!"。 - 数字(Number):可以是整数或浮点数,如
42、3.14。 - 布尔值(Boolean):只有两个值,
true或false。 - 空值(Null):用
null表示。
2. 复杂数据类型
对象---python字典
- 对象(Object):是无序的键值对集合,用花括号
{}表示。键必须是字符串,值可以是任意 JSON 数据类型。例如:{ "name": "John Doe", "age": 30, "isStudent": false } - 数组(Array):是有序的值列表,用方括号
[]表示。数组中的值可以是任意 JSON 数据类型。例如:- 读作,python,列表;
[ "apple", "banana", "orange" ]
- 读作,python,列表;
语法规则
- 键值对:对象中的键值对用冒号
:分隔,键值对之间用逗号,分隔。 - 元素分隔:数组中的元素用逗号
,分隔。 - 引号使用:字符串必须使用双引号
"包围,单引号不被允许。 - 注释:JSON 本身不支持注释,但在一些应用场景中,可以通过约定的方式添加注释信息。
示例
以下是一个更复杂的 JSON 示例,展示了对象和数组的嵌套使用:
{
"students": [
{
"name": "Alice",
"age": 20,
"grades": [
85,
90,
78
]
},
{
"name": "Bob",
"age": 21,
"grades": [
92,
88,
95
]
}
],
"classInfo": {
"className": "Math 101",
"teacher": "Mr. Smith"
}
}
# 就这个数据类型,手写yaml,转换出来。
这个 JSON 数据表示了一个班级的信息,包含多个学生的信息(存储在 students 数组中)以及班级的基本信息(存储在 classInfo 对象中)。
在不同编程语言中的应用
1. Python
Python 内置了 json 模块,用于处理 JSON 数据。
import json
# 将 Python 对象转换为 JSON 字符串
data = {
"name": "John",
"age": 30
}
# python数据类型,转换为json类型
json_str = json.dumps(data)
print(json_str)
# 将 JSON 字符串转换为 Python 对象
# 反序列化
json_str = '{"name": "John", "age": 30}'
data = json.loads(json_str)
print(data)
2. JavaScript
在 JavaScript 中,可以直接使用 JSON 对象的方法来处理 JSON 数据。
// 将 JavaScript 对象转换为 JSON 字符串
const data = {
name: "John",
age: 30
};
const jsonStr = JSON.stringify(data);
console.log(jsonStr);
// 将 JSON 字符串转换为 JavaScript 对象
const jsonStr = '{"name": "John", "age": 30}';
const dataObj = JSON.parse(jsonStr);
console.log(dataObj);
优点
- 简洁性:JSON 数据格式简洁明了,易于阅读和编写,减少了数据传输的体积。
- 跨平台:几乎所有的现代编程语言都支持 JSON 数据的解析和生成,方便不同系统之间的数据交换。
- 可扩展性:可以通过嵌套对象和数组的方式表示复杂的数据结构。
缺点
- 缺乏注释:JSON 本身不支持注释,对于复杂的配置文件或数据结构,理解起来可能会有一定困难。
- 严格的语法:JSON 的语法规则比较严格,例如字符串必须使用双引号,这可能会增加编写和调试的难度。
json语法
JSON 是一种数据格式。它本身是一串字符串,只是它有固定格式的字符串,符合这个数据格式要求的字符串,我们称之为JSON。
JSON可以和任意编程语言交互,C、golang、java、python等,再转变为编程语言特有的数据类型;
JSON键值对数据结构如上图,以 "{" 开始,以 "}" 结束。中间包裹的为Key : Value的数据结构。
在线格式化json
{
"name":"于超",
"age":18,
"hobby":[
"linux",
"python",
"music"
]
}
json数据类型
关于json咱们目前还不会去主动操作它,只需要看懂就行,比如命令的执行结果,是json格式的。
json语法规则
JSON 语法是 JavaScript 对象表示语法的子集。
数据在名称/值对中
数据由逗号分隔
大括号 {} 保存字典
中括号 [] 保存列表
键值对(字典)
JSON 数据的书写格式是:
key : value
{
"name":"超哥linux"
}
json值
json的值也就是value、可以是如下的数据类型
JSON 值可以是:
- 数字(整数或浮点数)
- 字符串(在双引号中)
- 逻辑值(true 或 false)
- 列表(在中括号中)
- 键值对(在大括号中)
- null
数字类型
{
"age":18
}
键值类型
可以有多个键值对,也可以嵌套
{
"name":"超哥linux",
"hoboy":{
"study":"linux,python",
"play":[
"movie",
"music"
]
}
}
列表
列表就是包裹了多个数据,json支持复杂的数据嵌套,通过这样的层级关系,可以很轻松的提取数据。
{
"name":"超哥linux",
"hoboy":{
"study":"linux,python",
"play":[
"movie",
"music"
],
"friends":[
{
"name":"alex",
"age":30
},
{
"name":"张三丰",
"age":500
}
]
}
}
布尔值
json的布尔值可以是真假值
{
"name":"灰太狼",
"female":false,
"是否能抓到羊":false,
"怕老婆":true
}
空值
{
"name":"灰太狼",
"female":false,
"是否能抓到羊":false,
"怕老婆":true,
"是否单身":null
}
json实际应用
账号密码传输
{
"username":"yc_uuu@163.com",
"password":"chaoge666"
}
json用在哪,网站的前后端数据传递,都是json格式
https://www.acgvod.com/
前面说了 JSON 是轻量级的文本数据交换格式,由于各个语言都支持 JSON
JSON 又支持各种数据类型,所以JSON常用于我们日常的 HTTP 交互、数据存储等。
天气API接口(json数据)
https://api.luffycity.com/api/v1/course/actual/?limit=3
GET
POST
PUT
DELETE
这就叫,restapi风格
路飞学城官网后端API,vue + python 前后端分离开发模式
https://www.json.cn/
部分数据
{
"code": 0,
"data": {
"count": 283,
"next": "/api/v1/course/actual/?limit=3&offset=3",
"previous": null,
"result": [
{
"id": 252,
"author": "alex金角大王",
"name": "Python 8天从入门到精通训练营",
"title": "路飞学城创始人",
"signature": "路飞学城创始人",
"brief": "8年从工资2.5k网管到年薪百万架构师+\r\n2016\\17年度51CTO全网十佳IT讲师\r\nTriaquae\\CrazyEye\\Madking 3款IT开源软件作者\r\n《Python编程基础》《Python全栈开发实战》作者\r\n抖音2021年度职业硬技能赛道第一名UP主\r\nB站知名技术UP主、抖音网红讲师、路飞学城创始人\r\n曾就职飞信、Nokia中国、中金公司、Advent、汽车之家"
}
]
}
}
ansible命令结果转为json格式
1.修改配置文件
[defaults]
stdout_callback = json
bin_ansible_callbacks = True
2.后续ansible命令执行结果,以json形式返回
[root@master-61 ~]#ansible backup -a 'hostname'
安装jq命令
jq 是一款命令行下处理 JSON 数据的工具。
其可以接受标准输入,命令管道或者文件中的 JSON 数据,经过一系列的过滤器(filters)和表达式的转后形成我们需要的数据结构并将结果输出到标准输出中。
jq命令可以格式化显示json信息
yum install jq -y
apt install jq -y
JQ用法
jq 是一个轻量级且灵活的命令行 JSON 处理器,在 Ubuntu 系统中,它能帮助用户解析、过滤、转换和格式化 JSON 数据。以下从多个方面详细介绍 jq 命令:
安装
在 Ubuntu 系统上,可使用 apt 包管理器来安装 jq:
sudo apt update
sudo apt install jq
基本语法
jq 的基本语法格式如下:
jq '过滤器表达式' 输入文件
或者从标准输入读取 JSON 数据:
命令 | jq '过滤器表达式'
其中,“过滤器表达式” 用于指定对 JSON 数据的处理规则。
常用过滤器及示例
1. 输出整个 JSON 对象
若想输出完整的 JSON 对象,可使用 . 作为过滤器。
echo '{"name": "John", "age": 30}' | jq '.'
输出结果:
{
"name": "John",
"age": 30
}
此示例中,jq '.' 会原样输出输入的 JSON 数据,并进行格式化,使其更易读。
2. 访问对象的属性
使用 .属性名 可访问 JSON 对象的特定属性。
echo '{"name": "John", "age": 30}' | jq '.name'
输出结果:
"John"
3. 访问数组元素
使用 .[索引] 来访问 JSON 数组中的特定元素,索引从 0 开始。
echo '[10, 20, 30]' | jq '.[1]'
echo '{"name": ["John","Bob"], "age": 30}' | jq '.name'
root@ansible-01:~/ansible_shell# echo '{"name": ["John","Bob"], "age": 30}' | jq '.name | .[0]'
"John"
输出结果:
20
4. 过滤和筛选
可结合条件表达式对 JSON 数据进行过滤和筛选。例如,筛选出数组中大于 15 的元素:
echo '[10, 20, 30]' | jq '.[] | select(. > 15)'
root@ansible-01:~/ansible_shell# echo '{"name": ["John","Bob"], "age": [30,35,8,18,28]}' |jq
{
"name": [
"John",
"Bob"
],
"age": [
30,
35
]
}
root@ansible-01:~/ansible_shell# echo '{"name": ["John","Bob"], "age": [30,35,8,18,28]}' |jq '.age |.[]|select(.>20)'
30
35
28
curl https://api.luffycity.com/api/v1/course/actual/?limit=3 | jq
输出结果:
20
30
这里,.[] 表示遍历数组中的每个元素,select(. > 15) 用于筛选出大于 15 的元素。
5. 处理嵌套对象和数组
对于嵌套的 JSON 结构,可通过连续使用属性名和索引来访问深层的数据。
echo '{"person": {"name": "John", "hobbies": ["reading", "running"]}}' | jq '.person.hobbies[0]'
root@ansible-01:~/ansible_shell# echo '{"person": {"name": "John", "hobbies": ["reading", "running"]}}' | jq '.person|.hobbies|.[]'
"reading"
"running"
输出结果:
"reading"
6. 格式化 JSON 数据
jq 会自动对输出的 JSON 数据进行格式化,使其具有良好的可读性。若输入的 JSON 数据格式混乱,可使用 jq '.' 进行格式化。
echo '{"name":"John","age":30}' | jq '.'
输出结果:
{
"name": "John",
"age": 30
}
常用选项
-c:以紧凑模式输出 JSON 数据,不进行格式化,减少输出的行数。
输出结果:echo '{"name": "John", "age": 30}' | jq -c '.'{"name": "John", "age": 30}-r:以原始字符串形式输出结果,去除字符串的引号。 ```bash echo '{"name": "John", "age": 30}' | jq -r '.name'
root@ansible-01:~/ansible_shell# echo '{"person": {"name": "John", "hobbies": ["reading", "running"]}}' | jq '.person|.hobbies|.[]' -r reading running
输出结果:
```plaintext
John
应用场景
- API 响应处理:在调用 RESTful API 时,返回的响应通常是 JSON 格式,使用
jq可以方便地提取所需的数据。 - 配置文件处理:对于 JSON 格式的配置文件,
jq可用于修改、验证和提取配置信息。 - 数据转换:将 JSON 数据转换为其他格式,或者对 JSON 数据进行结构转换。
简单的json数据提取
'{
"code": 0,
"data": {
"count": 283,
"next": "/api/v1/course/actual/?limit=3&offset=3",
"previous": null,
"result": [
{
"id": 252,
"author": "alex金角大王",
"name": "Python 8天从入门到精通训练营",
"title": "路飞学城创始人",
"signature": "路飞学城创始人",
"brief": "8年从工资2.5k网管到年薪百万架构师+\r\n2016\\17年度51CTO全网十佳IT讲师\r\nTriaquae\\CrazyEye\\Madking 3款IT开源软件作者\r\n《Python编程基础》《Python全栈开发实战》作者\r\n抖音2021年度职业硬技能赛道第一名UP主\r\nB站知名技术UP主、抖音网红讲师、路飞学城创始人\r\n曾就职飞信、Nokia中国、中金公司、Advent、汽车之家"
}
]
}
}'
[root@master-61 ~]#
[root@master-61 ~]#echo '{"name":"yuchao"}' | jq
{
"name": "yuchao"
}
[root@master-61 ~]#echo '{"name":"yuchao"}' | jq '.'
{
"name": "yuchao"
}
[root@master-61 ~]#echo '{"name":"yuchao"}' | jq '.name'
"yuchao"
多个值提取
必须符合json的数据类型要求
[root@master-61 ~]#echo '{"name":"yuchao","age":18,"male":"True"}' | jq '.name , .age, .male'
"yuchao"
18
"True"
[root@master-61 ~]#
[root@master-61 ~]#echo '{"name":"yuchao","age":18,"male":true}' | jq '.name , .age, .male'
"yuchao"
18
true
[root@master-61 ~]#echo '{"name":"yuchao","age":18,"male":false}' | jq '.name , .age, .male'
"yuchao"
18
false
串行执行(jq提供的管道符)
也就是字典套字典;
列表套字典;一层层嵌套,一层层拆,提取数据;
[root@master-61 ~]#echo '{"students":[{"name":"于超","age":18},{"name":"狗蛋","female":true},{"name":"三胖","address":"朝鲜"}]}'|jq
{
"students": [
{
"name": "于超",
"age": 18
},
{
"name": "狗蛋",
"female": true
},
{
"name": "三胖",
"address": "朝鲜"
}
]
}
# 一层层拆,先拆外面的字典
[root@master-61 ~]#echo '{"students":[{"name":"于超","age":18},{"name":"狗蛋","female":true},{"name":"三胖","address":"朝鲜"}]}'|jq '.students'
# 拆列表(默认提取所有列表数据)
[root@master-61 ~]#echo '{"students":[{"name":"于超","age":18},{"name":"狗蛋","female":true},{"name":"三胖","address":"朝鲜"}]}'|jq '.students | .[]'
# 提取字典数据(根据上一层提取列表数据的数量找)
[root@master-61 ~]#echo '{"students":[{"name":"于超","age":18},{"name":"狗蛋","female":true},{"name":"三胖","address":"朝鲜"}]}'|jq '.students | .[] | .name'
"于超"
"狗蛋"
"三胖"
指定列表序号
列表序号默认从0开始,依次增长
[root@master-61 ~]#echo '{"students":[{"name":"于超","age":18},{"name":"狗蛋","female":true},{"name":"三胖","address":"朝鲜"}]}'|jq '.students | .[0] '
[root@master-61 ~]#echo '{"students":[{"name":"于超","age":18},{"name":"狗蛋","female":true},{"name":"三胖","address":"朝鲜"}]}'|jq '.students | .[1] '
[root@master-61 ~]#echo '{"students":[{"name":"于超","age":18},{"name":"狗蛋","female":true},{"name":"三胖","address":"朝鲜"}]}'|jq '.students | .[2] '
提取出朝鲜的值
[root@master-61 ~]#echo '{"students":[{"name":"于超","age":18},{"name":"狗蛋","female":true},{"name":"三胖","address":"朝鲜"}]}'|jq '.students | .[2] | .address '
"朝鲜"
练习(提取天气json数据)
echo '{
"code": 0,
"data": {
"count": 283,
"next": "/api/v1/course/actual/?limit=3&offset=3",
"previous": null,
"result": [
{
"id": 252,
"author": "alex金角大王",
"name": "Python 8天从入门到精通训练营",
"title": "路飞学城创始人",
"signature": "路飞学城创始人兼百万主播",
"brief": "8年从工资2.5k网管到年薪百万架构师+\r\n2016\\17年度51CTO全网十佳IT讲师\r\nTriaquae\\CrazyEye\\Madking 3款IT开源软件作者\r\n《Python编程基础》《Python全栈开发实战》作者\r\n抖音2021年度职业硬技能赛道第一名UP主\r\nB站知名技术UP 主、抖音网红讲师、路飞学城创始人\r\n曾就职飞信、Nokia中国、中金公司、Advent、汽车之家"
}
]
}
}' | jq
作业
1. 提取 "/api/v1/course/actual/?limit=3&offset=3",
jq '.data|.next'
2. 同时提取,count,next,previous
jq '.data|.count,.next,.previous'
3. 提取,alex金角大王 路飞学城创始人兼百万主播
jq '.data|.result |.[]|.author,.signature'
大练习-json和yaml互相转化
以下为你提供一些 JSON 和 YAML 相互转换的练习及实现方法,使用常见的工具如 Python 和命令行工具来完成这些转换。
练习目标
- 掌握如何将 JSON 数据转换为 YAML 格式。
- 掌握如何将 YAML 数据转换为 JSON 格式。
示例数据
以下是示例的 JSON 和 YAML 数据,后续练习将基于这些数据进行转换。
JSON 示例
{
"students": [
{
"name": "Alice",
"age": 20,
"grades": [
85,
90,
78
]
},
{
"name": "Bob",
"age": 21,
"grades": [
92,
88,
95
]
}
],
"classInfo": {
"className": "Math 101",
"teacher": "Mr. Smith"
}
}
YAML 示例
试试,手写出yaml
students:
- name: Alice
age: 20
grades:
- 85
- 90
- 78
- name: Bob
age: 21
grades:
- 92
- 88
- 95
classInfo:
className: Math 101
teacher: Mr. Smith
使用 Python 进行转换
1. JSON 转 YAML
import json
import yaml
# pip install pyyaml
# cmd 如果出问题,问于超老师。
# 示例 JSON 数据
# JSON元生字符串,key,value,都得是双引号。
json_data = '''
{
"students": [
{
"name": "Alice",
"age": 20,
"grades": [85, 90, 78]
},
{
"name": "Bob",
"age": 21,
"grades": [92, 88, 95]
}
],
"classInfo": {
"className": "Math 101",
"teacher": "Mr. Smith"
}
}
'''
# 解析 JSON 数据
#
data = json.loads(json_data)
# 将数据转换为 YAML 格式
yaml_output = yaml.dump(data, allow_unicode=True, default_flow_style=False)
print(yaml_output)
在上述代码中,首先使用 json.loads() 方法将 JSON 字符串解析为 Python 对象,然后使用 yaml.dump() 方法将 Python 对象转换为 YAML 字符串并打印输出。
2. YAML 转 JSON
import json
import yaml
# 示例 YAML 数据
yaml_data = '''
students:
- name: Alice
age: 20
grades:
- 85
- 90
- 78
- name: Bob
age: 21
grades:
- 92
- 88
- 95
classInfo:
className: Math 101
teacher: Mr. Smith
'''
# 解析 YAML 数据
data = yaml.safe_load(yaml_data)
# 将数据转换为 JSON 格式
json_output = json.dumps(data, indent=4, ensure_ascii=False)
print(json_output)
这里使用 yaml.safe_load() 方法将 YAML 字符串解析为 Python 对象,再使用 json.dumps() 方法将 Python 对象转换为格式化后的 JSON 字符串并输出。
使用命令行工具进行转换
安装工具
在 Ubuntu 系统上,可以使用 jq 处理 JSON 数据,使用 yq 处理 YAML 数据。
sudo apt update
sudo apt install jq
pip install yq
1. JSON 转 YAML
将 JSON 数据保存为 data.json 文件,然后使用以下命令将其转换为 YAML 格式:
cat data.json | yq -P
-P 选项用于以漂亮的格式输出 YAML 数据。
2. YAML 转 JSON
将 YAML 数据保存为 data.yaml 文件,使用以下命令将其转换为 JSON 格式:
yq -j data.yaml
-j 选项用于将 YAML 数据转换为 JSON 格式输出。
练习建议
- 自己创建不同结构的 JSON 和 YAML 数据,然后进行相互转换,加深对转换过程的理解。
- 尝试处理包含嵌套结构、数组、复杂对象等不同类型数据的转换,提高处理复杂数据的能力。
实战rsync剧本开发
先写好ad-hoc模式(服务端)
运维部署初始化。
以下是一个使用 Ansible Ad - Hoc 命令部署 rsync 服务端的 Bash 脚本。该脚本会根据目标主机的操作系统类型(Debian 系或 Red Hat 系)进行相应的操作,包括安装 rsync、复制配置文件、创建认证文件、创建共享目录以及启动服务等。
#!/bin/bash
# 1. 服务本身,rsync部署逻辑 2.bash脚本开发流程 3.ansible使用流程 4.不断迭代,修复bug,基本可以使用的脚本,v1 ,v2
# 定义目标主机组
RSYNC_SERVERS="rsync_servers"
# 定义本地配置文件和认证文件路径
RSYNC_CONFIG_SRC="./rsyncd.conf"
RSYNC_SECRETS_SRC="./rsyncd.secrets"
# 定义共享目录路径
SHARE_DIR="/data/backup"
# 函数:检查系统类型
function get_os_family() {
ansible $RSYNC_SERVERS -m setup -a "filter=ansible_os_family" | awk -F': ' '/ansible_os_family/ {print $2}' | tr -d '"'
}
# 函数:安装 rsync
function install_rsync() {
local os_family=$(get_os_family)
if [ "$os_family" = "Debian" ]; then
ansible $RSYNC_SERVERS -m apt -a "name=rsync state=present update_cache=yes"
else
ansible $RSYNC_SERVERS -m yum -a "name=rsync state=present"
fi
}
# 函数:复制配置文件
function copy_config() {
ansible $RSYNC_SERVERS -m copy -a "src=$RSYNC_CONFIG_SRC dest=/etc/rsyncd.conf mode=0644"
}
# 函数:创建认证文件
function create_secrets() {
echo "rsyncuser:password" > $RSYNC_SECRETS_SRC
chmod 0600 $RSYNC_SECRETS_SRC
ansible $RSYNC_SERVERS -m copy -a "src=$RSYNC_SECRETS_SRC dest=/etc/rsyncd.secrets mode=0600"
}
# 函数:创建共享目录
function create_share_dir() {
ansible $RSYNC_SERVERS -m file -a "path=$SHARE_DIR state=directory mode=0755 owner=nobody group=nobody"
}
# 函数:启动并设置开机自启
function start_rsync() {
local os_family=$(get_os_family)
if [ "$os_family" = "Debian" ]; then
ansible $RSYNC_SERVERS -m service -a "name=rsync state=started enabled=yes"
else
ansible $RSYNC_SERVERS -m systemd -a "name=rsyncd state=started enabled=yes"
fi
}
# 安装 rsync
echo "开始安装 rsync..."
install_rsync
echo "rsync 安装完成。"
# 复制配置文件
echo "开始复制配置文件..."
copy_config
echo "配置文件复制完成。"
# 创建认证文件
echo "开始创建认证文件..."
create_secrets
echo "认证文件创建完成。"
# 创建共享目录
echo "开始创建共享目录..."
create_share_dir
echo "共享目录创建完成。"
# 启动并设置开机自启
echo "开始启动 rsync 服务并设置开机自启..."
start_rsync
echo "rsync 服务已启动并设置开机自启。"
使用说明
- 保存脚本:将上述脚本保存为一个文件,例如
deploy_rsync_server.sh。 - 赋予执行权限:在终端中执行
chmod +x deploy_rsync_server.sh。 - 修改主机组:根据你的 Ansible 主机清单文件,修改脚本中
RSYNC_SERVERS变量的值,使其对应实际的主机组名称。 - 准备配置文件:确保本地存在
rsyncd.conf配置文件,内容可参考以下示例: ```plaintext/etc/rsyncd.conf
全局配置
uid = nobody gid = nobody use chroot = yes max connections = 4 pid file = /var/run/rsyncd.pid exclude = lost+found/ transfer logging = yes timeout = 900 ignore nonreadable = yes dont compress = .gz .tgz .zip .z .Z .rpm .deb .bz2
模块配置
[mybackup] path = /mybackup comment = Backup directory read only = no list = yes auth users = yuchao secrets file = /etc/rsyncd.secrets
5. **执行脚本**:在终端中运行 `./deploy_rsync_server.sh`。
### 注意事项
- 请根据实际情况调整 `rsyncd.conf` 中的配置信息,如共享目录路径、认证用户等。
- 认证文件中的用户名和密码可以根据需要进行修改。
- 确保 Ansible 控制节点能够正常连接到目标主机,并且具备相应的权限。
### 改造为playbook剧本
可以参考官网写法
https://docs.ansible.com/ansible/latest/user_guide/playbooks_intro.html#playbook-execution
以下是一个优化后的 Ansible Playbook 剧本,用于部署 `rsync` 服务端。该剧本会根据目标主机的操作系统类型(Debian 系或 Red Hat 系)进行相应的操作,包含安装 `rsync`、复制配置文件、创建认证文件、创建共享目录以及启动服务等步骤。
nginx
各类软件,配置文件名字nginx.conf my.cnf redis.conf
Mysql -uroot -ppwd123
redis auth 密码
Mysql 备份,备份目录
- ansible,部署一个rsync服务端。。。。。。。。。。。
部署思路,设备 作业,2个剧本
1. ansible机器,即是rsync机器,剧本该如何写,本地化部署一个rsync服务,本地化管理
2. ansible,rsync是2台机器,文件分发,都远程管理
3. 新机器,如何快速用ansible进行免密管理,写一个shell脚本快速初始化。
- apt源修改清华,安装基础软件,vim,net-tools,lsof等
- ntp时间
- 主机名
- 静态ip
- ssh免密管理
- sudo配置
4. 实现ansible,免密sudo远程管理rsync01机器
ansible01机器 10.211.55.10 rsync01
```yaml
---
- name: Deploy rsync server
hosts: rsync_servers
become: true
gather_facts: yes
vars:
rsync_config_src: "./rsyncd.conf"
rsync_secrets_src: "./rsyncd.secrets"
share_dir: "/data/backup"
rsync_user: "rsyncuser"
rsync_password: "password"
tasks:
- name: Install rsync on Debian-based systems
apt:
name: rsync
state: present
update_cache: yes
when: ansible_os_family == "Debian"
- name: Install rsync on Red Hat-based systems
yum:
name: rsync
state: present
when: ansible_os_family == "RedHat"
- name: Copy rsync configuration file
copy:
# playbook剧本下,的变量替换,是基于jinja2的模板渲染语法而来
# "{{ 自定义变量 }}"
# 部署节点的本地,ansible机器
src: "{{ rsync_config_src }}"
dest: /etc/rsyncd.conf
mode: '0644'
- name: Create rsync secrets file locally
copy:
content: "{{ rsync_user }}:{{ rsync_password }}"
dest: "{{ rsync_secrets_src }}"
mode: '0600'
# delegate_to参数指定该任务将在本地主机(即执行 Ansible 的控制节点)上执行,而不是在 Playbook 中指定的目标主机上执行。
delegate_to: localhost
- name: Copy rsync secrets file to remote hosts
copy:
src: "{{ rsync_secrets_src }}"
dest: /etc/rsyncd.secrets
mode: '0600'
- name: Create shared directory
file:
path: "{{ share_dir }}"
state: directory
mode: '0755'
owner: nobody
group: nobody
- name: Start and enable rsync service on Debian-based systems
systemd:
name: rsync
state: started
enabled: yes
when: ansible_os_family == "Debian"
- name: Start and enable rsync service on Red Hat-based systems
systemd:
name: rsyncd
state: started
enabled: yes
when: ansible_os_family == "RedHat"
使用说明
1. 保存剧本
将上述内容保存为一个 YAML 文件,例如 deploy_rsync_server.yml。
2. 准备配置文件
确保本地存在 rsyncd.conf 配置文件,示例内容如下:
# /etc/rsyncd.conf
# 全局配置
uid = nobody
gid = nobody
use chroot = yes
max connections = 4
pid file = /var/run/rsyncd.pid
exclude = lost+found/
transfer logging = yes
timeout = 900
ignore nonreadable = yes
dont compress = *.gz *.tgz *.zip *.z *.Z *.rpm *.deb *.bz2
# 模块配置
[backup]
path = /data/backup
comment = Backup directory
read only = no
list = yes
auth users = rsyncuser
secrets file = /etc/rsyncd.secrets
3. 调整变量
可以根据实际需求修改 Playbook 中的变量,如 rsync_user、rsync_password、share_dir 等。
4. 执行剧本
使用以下命令执行 Playbook:
ansible-playbook deploy_rsync_server.yml
注意事项
- 确保 Ansible 控制节点能够通过 SSH 连接到目标主机,并且具备
sudo权限(因为使用了become: true)。 - 根据实际情况调整
rsyncd.conf中的配置信息,如共享目录路径、认证用户等。 - 该剧本假设目标主机的
rsync服务在 Debian 系系统中名为rsync,在 Red Hat 系系统中名为rsyncd。
测试palybook执行
剧本编写完毕后,得执行才能开始工作。
在Ansible程序里,加载模块的功能可以直接用ansible命令操作(ad-hoc)
加载剧本中的功能,可以使用ansible-playbook命令(playbook)
-C参数
-C 或 --check 参数用于以 “检查模式”(也称为 “模拟执行模式”)运行 Ansible Playbook。
在检查模式下,Ansible 会模拟执行 Playbook 中的所有任务,但不会对目标主机进行任何实际的更改。它会分析每个任务执行后可能产生的影响,并输出相应的结果信息,包括哪些任务会导致目标主机的状态发生改变,哪些任务不会产生改变等。
添加-C参数,可以模拟剧本的执行,但是不会产生实际改变
[root@master-61 /my-playbook]#ansible-playbook -C install_rsync.yaml
注意别忘记,剧本中需要的配置文化,你得提前准备好
(就好比你要拍一部枪战片,电源都开拍了,你连道具枪还没准备好)
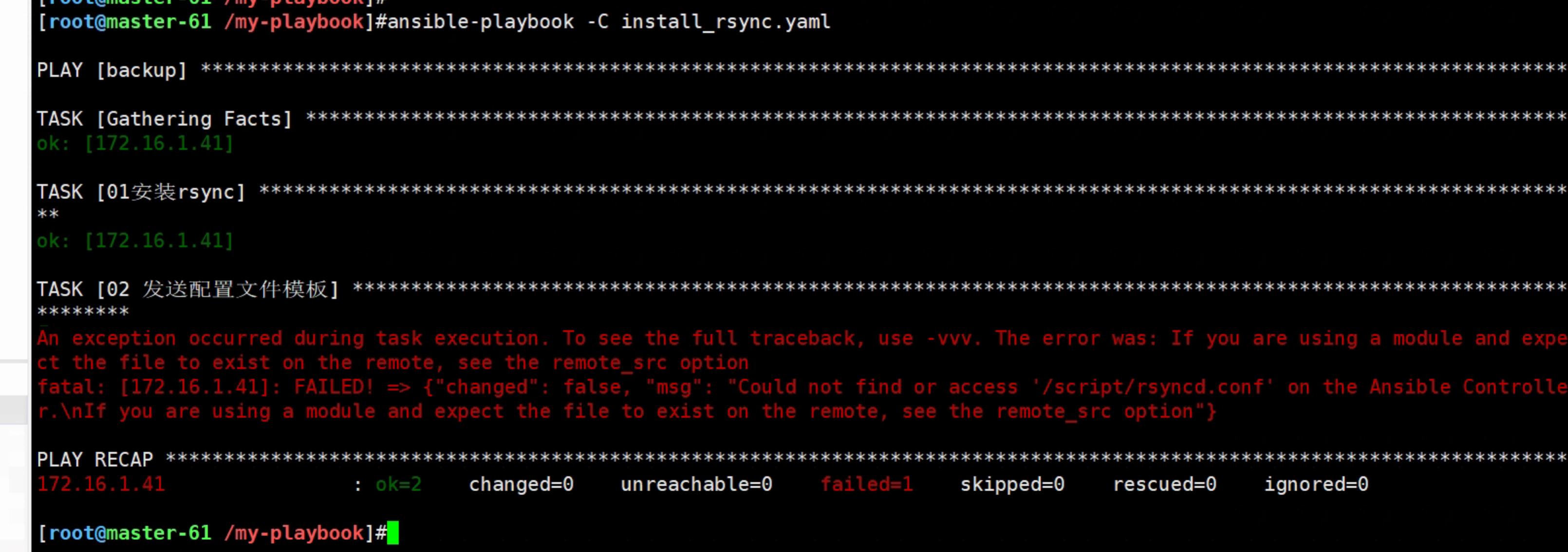
剧本执行过程中会产生响应的输出,根据输出的信息可以掌握剧本是否正确执行,根据输出的措施信息,可以掌握剧本中编写的逻辑错误。
当本地执行了任务,会得到返回值changed
如果不需要执行了,得到返回值ok
创建rsync配置文件,密码文件
注意是master-61机器
[root@master-61 /my-playbook]#cat /script/rsyncd.conf
uid = www
gid = www
port = 873
fake super = yes
use chroot = no
max connections = 200
timeout = 600
ignore errors
read only = false
list = false
auth users = rsync_backup
secrets file = /etc/rsync.passwd
log file = /var/log/rsyncd.log
[backup]
comment = chaoge rsync backup!
path = /backup
[data]
comment = yuchaoit.cn rsync!
path = /data
密码文件
[root@master-61 /my-playbook]#cat /script/rsync.passwd
rsync_backup:yuchao666
再次测试执行
[root@master-61 /my-playbook]#ansible-playbook -C install_rsync.yaml
结果
PLAY RECAP ************************************************************************************************************************
172.16.1.41 : ok=9 changed=7 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
实质性执行playbook
[root@master-61 /my-playbook]#ansible-playbook install_rsync.yaml
检查rsyncd部署情况(必须验证你的部署情况)
[root@master-61 /my-playbook]#ansible backup -a "ls -l /etc/rsync.passwd"
172.16.1.41 | CHANGED | rc=0 >>
-rw------- 1 root root 23 Apr 26 17:05 /etc/rsync.passwd
[root@master-61 /my-playbook]#ansible backup -a "cat /etc/rsync.passwd"
172.16.1.41 | CHANGED | rc=0 >>
rsync_backup:yuchao666
[root@master-61 /my-playbook]#ansible backup -a "systemctl status rsyncd"
测试rsync是否可用
[root@master-61 /my-playbook]#export RSYNC_PASSWORD=yuchao666
[root@master-61 /my-playbook]#rsync -avzp /tmp/chaoge.log rsync_backup@rsync-41::data
[root@master-61 /my-playbook]#ansible backup -a "ls /data"
172.16.1.41 | CHANGED | rc=0 >>
chaoge.log
实战NFS剧本开发
以下是一个用于在生产环境中部署和配置 NFS(Network File System)服务的 Ansible Playbook 案例,包含 NFS 服务器和客户端的部署、配置以及挂载操作。
环境假设
- 目标主机分为 NFS 服务器组和 NFS 客户端组,分别在 Ansible 主机清单文件中定义为
nfs_servers和nfs_clients。 - 服务器端将共享
/data/nfs_share目录。 - 客户端将该共享目录挂载到
/mnt/nfs_share目录。
Playbook 内容
---
- name: Deploy and configure NFS server
hosts: nfs_servers
become: true
gather_facts: yes
tasks:
- name: Install NFS server packages on Debian-based systems
apt:
name:
- nfs-kernel-server
state: present
update_cache: yes
when: ansible_os_family == "Debian"
- name: Install NFS server packages on Red Hat-based systems
yum:
name:
- nfs-utils
- rpcbind
state: present
when: ansible_os_family == "RedHat"
- name: Create NFS shared directory
file:
path: /data/nfs_share
state: directory
mode: '0777'
- name: Configure NFS exports
lineinfile:
path: /etc/exports
line: '/data/nfs_share *(rw,sync,no_subtree_check)'
create: yes
- name: Export NFS shares
command: exportfs -a
changed_when: false
- name: Start and enable NFS server services on Debian-based systems
service:
name: "{{ item }}"
state: started
enabled: yes
loop:
- nfs-kernel-server
when: ansible_os_family == "Debian"
- name: Start and enable NFS server services on Red Hat-based systems
systemd:
name: "{{ item }}"
state: started
enabled: yes
loop:
- rpcbind
- nfs-server
when: ansible_os_family == "RedHat"
- name: Deploy and configure NFS clients
hosts: nfs_clients
become: true
gather_facts: yes
tasks:
- name: Install NFS client packages on Debian-based systems
apt:
name:
- nfs-common
state: present
update_cache: yes
when: ansible_os_family == "Debian"
- name: Install NFS client packages on Red Hat-based systems
yum:
name:
- nfs-utils
- rpcbind
state: present
when: ansible_os_family == "RedHat"
- name: Create mount point on clients
file:
path: /mnt/nfs_share
state: directory
mode: '0777'
- name: Mount NFS share
mount:
path: /mnt/nfs_share
src: "{{ hostvars[groups['nfs_servers'][0]]['ansible_default_ipv4']['address'] }}:/data/nfs_share"
fstype: nfs
state: mounted
详细解释
1. NFS 服务器部署部分
- 安装软件包:根据目标主机的操作系统类型(Debian 或 Red Hat),使用
apt或yum安装 NFS 服务器所需的软件包。 - 创建共享目录:使用
file模块在服务器上创建/data/nfs_share目录,并设置权限为0777。 - 配置
exports文件:使用lineinfile模块在/etc/exports文件中添加共享目录的配置信息。 - 导出共享目录:使用
command模块执行exportfs -a命令,使共享目录配置生效。 - 启动并启用服务:根据操作系统类型,使用
service或systemd模块启动并启用 NFS 服务器相关服务。
2. NFS 客户端部署部分
- 安装软件包:根据目标主机的操作系统类型,使用
apt或yum安装 NFS 客户端所需的软件包。 - 创建挂载点:使用
file模块在客户端上创建/mnt/nfs_share目录,并设置权限为0777。 - 挂载共享目录:使用
mount模块将 NFS 服务器的共享目录挂载到客户端的/mnt/nfs_share目录。这里使用hostvars获取 NFS 服务器的 IP 地址。
使用方法
- 保存 Playbook:将上述内容保存为一个 YAML 文件,例如
nfs_deployment.yml。 - 准备主机清单文件:确保在 Ansible 主机清单文件中定义了
nfs_servers和nfs_clients主机组,并包含相应的主机信息。 - 执行 Playbook:使用以下命令执行 Playbook:
ansible-playbook nfs_deployment.yml
注意事项
- 确保 Ansible 控制节点能够通过 SSH 连接到目标主机,并且具备
sudo权限(因为使用了become: true)。 - 根据实际情况调整共享目录的路径、权限以及挂载点的设置。
- 如果有多个 NFS 服务器,需要根据实际情况修改获取服务器 IP 地址的逻辑。
1.先写好ad-hoc模式部署nfs
基于ad-hoc转换为playbook更不容易出错,建议你这样去转化
# 1.安装nfs-utils rpcbind服务
ansible nfs -m yum -a "name=nfs-utils state=installed"
ansible nfs -m yum -a "name=rpcbind state=installed"
# 2.创建nfs限定的用户、组
ansible nfs -m group -a "name=www gid=1000"
ansible nfs -m user -a 'name=www uid=1000 group=www create_home=no shell=/sbin/nologin'
# 3.创建共享目录
ansible nfs -m file -a 'path=/data owner=www group=www state=directory'
# 4.拷贝配置文件,发给nfs机器
ansible nfs -m copy -a 'src=/script/exports dest=/etc/exports'
# 5.启动nfs服务,设置开机自启
ansible nfs -m systemd -a 'name=nfs state=started enabled=yes'
2.创建nfs配置文件
在master-61机器
[root@master-61 ~]#cat /script/exports
/data 172.16.1.0/24(rw,sync,all_squash,anonuid=1000,anongid=1000)
3.改造playbook(变量风格)nfs服务端
- hosts: nfs
tasks:
- name: 01 安装nfs-utils 服务
yum: name=nfs-utils state=installed
- name: 02 安装rpcbind 服务
yum: name=rpcbind state=installed
- name: 03 创建组
group: name=www gid=1000
- name: 04 创建用户
user: name=www uid=1000 group=www create_home=no shell=/sbin/nologin
- name: 05 创建共享目录
file: path=/data owner=www group=www state=directory
- name: 06 拷贝配置文件
copy: src=/script/exports dest=/etc/exports
- name: 07 启动nfs
systemd: name=nfs state=started enabled=yes
4.web789客户端playbook
部署nginx运行环境
[root@master-61 /script]#cat nginx.conf
user www www;
worker_processes auto;
worker_rlimit_nofile 65535;
events{
use epoll;
worker_connections 65535;
}
http{
include mime.types;
default_type application/octet-stream;
charset utf-8;
server{
listen 80;
server_name localhost;
root /usr/share/nginx/html;
location / {
index index.html;
}
}
}
playbook
- hosts: web
tasks:
- name: 01 install nginx
yum: name=nginx state=installed
- name: 02 add group
group: name=www gid=1000
- name: 03 add www user
user: name=www uid=1000 group=www create_home=no shell=/sbin/nologin
- name: 04 copy nginx.conf
copy: src=/script/nginx.conf dest=/etc/nginx/nginx.conf
- name: 05 start nginx
systemd: name=nginx state=restarted enabled=yes
执行剧本
[root@master-61 /script]#ansible-playbook install_nginx.yaml
测试结果
[root@master-61 /script]#ansible web -m shell -a "ss -tunlp|grep nginx"
172.16.1.9 | CHANGED | rc=0 >>
tcp LISTEN 0 128 *:80 *:* users:(("nginx",pid=37661,fd=6),("nginx",pid=37658,fd=6))
172.16.1.8 | CHANGED | rc=0 >>
tcp LISTEN 0 128 *:80 *:* users:(("nginx",pid=8007,fd=6),("nginx",pid=8004,fd=6))
172.16.1.7 | CHANGED | rc=0 >>
tcp LISTEN 0 128 *:80 *:* users:(("nginx",pid=12210,fd=6),("nginx",pid=12207,fd=6))
5.web789挂载nfs
关于用户、组、已经存在了就别创建了
- hosts: web
tasks:
- name: 01 安装nfs-utils 服务
yum: name=nfs-utils state=installed
- name: 02 安装rpcbind 服务
yum: name=rpcbind state=installed
- name: 05 启动rpcbind服务
systemd: name=rpcbind state=started enabled=yes
- name: 06 挂载nfs
mount: src=172.16.1.31:/data path=/usr/share/nginx/html fstype=nfs opts=defaults state=mounted
测试执行
[root@master-61 /script]#ansible-playbook mount_nfs_web.yaml
在共享存储中,创建测试数据
[root@nfs-31 /data]#vim index.html
[root@nfs-31 /data]#chown -R www.www index.html
[root@nfs-31 /data]#
测试访问nginx
[root@master-61 /script]#curl 10.0.0.7
<meta charset=utf-8>
于超老师带你学ansible
[root@master-61 /script]#curl 10.0.0.8
<meta charset=utf-8>
于超老师带你学ansible
[root@master-61 /script]#curl 10.0.0.9
<meta charset=utf-8>
于超老师带你学ansible
给nfs服务端添加实时同步lsyncd
依旧是先写好ad-hoc模式
ansible nfs -m yum -a 'name=lsyncd state=installed'
ansible nfs -m group -a 'name=www gid=1000'
ansible nfs -m user -a 'name=www uid=1000 group=www create_home=no shell=/sbin/nologin'
ansible nfs -m copy -a 'src=/script/lsyncd.conf dest=/etc/lsyncd.conf'
ansible nfs -m copy -a 'src=/script/lsyncd.passwd dest=/etc/lsyncd.passwd mode=600'
ansible nfs -m systemd -a 'name=lsyncd state=started'
配置文件
settings {
logfile ="/var/log/lsyncd/lsyncd.log",
statusFile ="/var/log/lsyncd/lsyncd.status",
inotifyMode = "CloseWrite",
maxProcesses = 8,
}
sync {
default.rsync,
source = "/data",
target = "rsync_backup@172.16.1.41::data",
delete= true,
exclude = {".*"},
delay=1,
rsync = {
binary = "/usr/bin/rsync",
archive = true,
compress = true,
verbose = true,
password_file="/etc/lsyncd.passwd",
_extra={"--bwlimit=200"}
}
}
密码文件
[root@master-61 /script]#cat /script/lsyncd.passwd
yuchao666
改造playbook(两种语法风格、字典形式、变量形式)
www用户、组有了就别创建了
- hosts: nfs
tasks:
- name: 01 install lsyncd
yum: name=lsyncd state=installed
- name: 04 copy lsyncd.conf
copy: src=/script/lsyncd.conf dest=/etc/lsyncd.conf
- name: 05 copy lsync.password
copy: src=/script/lsyncd.passwd dest=/etc/lsyncd.passwd mode=600
- name: 06 start lsyncd services
systemd: name=lsyncd state=started
测试剧本
[root@master-61 /script]#ansible-playbook -C install_lsyncd.yaml
执行剧本,查看实时同步结果
[root@master-61 /script]#ansible-playbook install_lsyncd.yaml
创建客户端测试数据
[root@master-61 /script]#ansible web -m shell -a "touch /usr/share/nginx/html/t{1..10}.png"
查看实时同步的数据
[root@master-61 /script]#ansible backup -a "ls /data"