10-shell数组
学习Bash数组对于提升Linux系统管理和脚本编写能力非常重要,尤其是在自动化任务、批量处理和系统管理方面。以下是学习Bash数组的原因、应用场景以及如何学习的详细说明:
为什么学习Bash数组?
高效处理批量数据
- Bash数组可以存储多个值(如文件名、IP地址、用户列表等),方便批量操作。
- 例如,遍历数组中的文件名进行批量重命名或处理。
简化脚本逻辑
- 使用数组可以避免重复代码,使脚本更简洁、易读。
- 例如,将多个命令参数存储到数组中,动态调用。
系统管理必备技能
- 在Linux服务器管理中,数组常用于处理日志、监控系统状态、批量管理用户等任务。
- 例如,批量检查多个服务的运行状态。
提高脚本灵活性
- 数组支持动态增删改查,适合处理不确定数量的数据。
- 例如,从文件中读取数据并存储到数组中进行处理。
与其他工具结合
- Bash数组可以与Linux命令(如
grep、awk、sed)结合,实现更强大的功能。 - 例如,将
grep的结果存储到数组中,进一步处理。
- Bash数组可以与Linux命令(如
Bash数组的应用场景
批量文件操作
- 遍历目录中的文件,批量修改权限或移动文件。
files=(*.txt) for file in "${files[@]}"; do mv "$file" "backup_$file" done
- 遍历目录中的文件,批量修改权限或移动文件。
系统监控与管理
- 检查多个服务的状态。
services=("nginx" "mysql" "redis") for service in "${services[@]}"; do systemctl status "$service" >> svc.log 2>&1 done
- 检查多个服务的状态。
日志分析与处理
- 将日志文件中的特定行存储到数组中,进行统计或分析。
- 数一数,系统日志,某个日志,某个信息,大约有多少行。
- 数一数,系统中有多少个用户是允许登录。
log_lines=($(grep "ERROR" /var/log/syslog)) echo "Found ${#log_lines[@]} errors."
动态参数传递
- 将命令行参数存储到数组中,灵活调用。
- 核心知识点
$@和${array[@]}展开时必须用双引号包裹,才能保留元素中的空格- 带空格的参数传递时必须使用引号包裹,否则会被视为多个参数
- Shell的单词拆分(Word Splitting)机制会导致未加引号的变量展开时按空格拆分为多个参数
# args数组,里面几个元素?3个 args=( "$@" ) for arg in "${args[@]}"; do echo "Argument: $arg" done
数据处理与转换
- 从CSV文件中读取数据并存储到数组中,进行进一步处理。
IFS=',' read -r -a data <<< "apple,banana,cherry" echo "$(set|grep data)" echo "First item: ${data[0]}" echo "${data[@]} 一共有${#data[@]}个元素"
- 从CSV文件中读取数据并存储到数组中,进行进一步处理。
如何学习Bash数组?
掌握基础语法
- 声明数组:
array=(value1 value2 value3) - 访问元素:
${array[index]} - 获取数组长度:
${#array[@]} - 遍历数组:
for item in "${array[@]}"; do ... done
- 声明数组:
实践小脚本
- 从简单的任务开始,如批量重命名文件、统计日志错误等。
- 逐步尝试更复杂的场景,如结合
awk、sed处理数据。
阅读优秀脚本
- 参考开源项目中的Bash脚本,学习数组的高级用法。
- 例如,GitHub上的Linux自动化脚本。
结合实际问题
- 在工作中遇到批量任务时,尝试用数组优化脚本。
- 例如,批量创建用户、检查服务器状态等。
参考文档与教程
总结
学习Bash数组可以显著提升脚本编写效率和系统管理能力,尤其是在处理批量数据、自动化任务和系统监控方面。通过掌握基础语法、实践小脚本并结合实际需求,你可以快速掌握这一技能,并在工作中创造更多价值。
1.数组介绍
1. 数组用于存储多个值,且提供索引标号便于取值
2. Bash支持普通的数值索引数组,还支持关联数组。
数组是最常见的数据结构,可以用来存放多个数据。
有两种类型的数组:数值索引类型数组和关联数组。
数值索引类型数组使用0、1、2、3…数值作为索引,通过索引可找到数组中对应位置的数据
关联数组使用名称(通常是字符串,但某些语言中支持其它类型)作为索引,是key/value模式的结构,key是索引,value是对应元素的值。
通过key索引可找到关联数组中对应的数据value
关联数组在其它语言中也称为map、hash结构、dict等。
打不死股,从严格意义上来说,关联数组不是数组,它不符合数组数据结构,只是因为访问方式类似于数值索引类型的数组,才在某些语言中称之为关联数组。
数值索引类型的数组中存放的每个元素在内存中连续的,只要知道第一个元素的地址,就能计算出第2个元素地址、第3个元素地址、第N个元素地址。
为了方便访问数组中的每一个元素,shell通过索引(下标)来一一对应每一个元素;
索引从0开始。
2.数组分类
在Bash中,数组可以分为索引数组和关联数组两大类。每种类型都有其特定的用途和语法。以下是详细的分类说明:
1. 索引数组(Indexed Arrays)
索引数组是最常见的数组类型,使用整数作为索引(从0开始)。它适合存储有序的数据列表。
特点
- 索引为整数,默认从0开始。
- 可以动态增删元素。
- 适合存储顺序数据(如文件名列表、IP地址列表等)。
声明与初始化
# 直接初始化
array=("apple" "banana" "cherry")
# 逐个赋值
# 增删改查
array[0]="apple"
array[1]="banana"
array[2]="cherry"
访问元素
echo ${array[0]} # 输出:apple
echo ${array[1]} # 输出:banana
遍历数组
for item in "${array[@]}"; do
echo "$item"
done
获取数组长度
echo ${#array[@]} # 输出:3
添加元素
array+=("date") # 添加一个新元素
删除元素
unset array[1] # 删除索引为1的元素
2. 关联数组(Associative Arrays)
关联数组使用字符串作为键(key),类似于其他编程语言中的字典(dictionary)或哈希表(hash map)。
它适合存储键值对形式的数据。
Key:value
特点
- 键为字符串,值可以是任意数据。
- 需要Bash 4.0及以上版本支持。
- 适合存储非顺序数据(如配置项、用户信息等)。
声明与初始化
# 声明关联数组
declare -A stu_info
# 初始化
# 再执行这个操作呢???再执行,等于覆盖,修改key值
stu_info=(
["name"]="bob"
["age"]=41
["city"]="Jiang su"
["hobby"]="Python linux"
)
# 逐个赋值
stu_info["name"]="yuchao"
stu_info["age"]=30
stu_info["city"]="bei jing"
访问元素
echo ${assoc_array["name"]} # 输出:Alice
echo ${assoc_array["age"]} # 输出:25
遍历数组
# 取key
for key in "${!stu_info[@]}"; do
# 打印,某个key,对应的值是什么
# 循环提取,打印 key:value
echo "$key: ${stu_info[$key]}"
done
# 取key
[root@www.yuchaoit.cn all_bash_file]$for k in "${!stu_info[@]}";do echo $k ;done
for k in "${!stu_info[@]}";do echo $k ;done
city
age
hobby
name
# 取value
[root@www.yuchaoit.cn all_bash_file]$for k in "${stu_info[@]}";do echo $k ;done
for k in "${stu_info[@]}";do echo $k ;done
Jiang su
41
Python linux
bob
获取数组长度
echo ${#assoc_array[@]} # 输出:3
添加元素
assoc_array["country"]="USA" # 添加一个新键值对
删除元素
unset assoc_array["age"] # 删除键为"age"的元素
3. 多维数组(模拟)
Bash本身不支持真正的多维数组,但可以通过嵌套索引数组或关联数组来模拟多维数组。
模拟二维索引数组
declare -a matrix
matrix[0]="1 2 3"
matrix[1]="4 5 6"
matrix[2]="7 8 9"
# 访问元素
row=(${matrix[1]})
echo ${row[1]} # 输出:5
模拟二维关联数组
declare -A matrix
matrix["0,0"]="1"
matrix["0,1"]="2"
matrix["1,0"]="3"
matrix["1,1"]="4"
# 访问元素
echo ${matrix["1,0"]} # 输出:3
4. 稀疏数组
Bash数组支持稀疏存储,即数组的索引可以不连续。
示例
array=()
array[0]="apple"
array[10]="banana"
echo ${array[0]} # 输出:apple
echo ${array[10]} # 输出:banana
echo ${#array[@]} # 输出:2(只有两个元素)
总结
- 索引数组:适合存储有序列表,索引为整数。
- 关联数组:适合存储键值对,键为字符串。
- 多维数组:通过嵌套数组模拟。
- 稀疏数组:支持不连续索引。
根据具体需求选择合适的数组类型,可以显著提高脚本的效率和可读性。
1. 普通数组 :
就是一个数组变量,有多个值,取值通过整数索引号取即可
2. 关联数组
自定义索引名,取值玩法是
数组变量[索引] 拿到值
3.数组变量定义实践
在Bash中,数组变量的定义和操作非常灵活。以下是一些常见的数组定义实践示例,涵盖索引数组、关联数组以及多维数组的模拟。
1. 索引数组的定义与实践
索引数组是最常用的数组类型,适合存储有序列表。
定义与初始化
# 直接初始化
fruits=("apple" "banana" "cherry")
# 逐个赋值
fruits[0]="apple"
fruits[1]="banana"
fruits[2]="cherry"
访问元素
echo ${fruits[0]} # 输出:apple
echo ${fruits[1]} # 输出:banana
遍历数组
for fruit in "${fruits[@]}"; do
echo "$fruit"
done
获取数组长度
echo ${#fruits[@]} # 输出:3
添加元素
fruits+=("date") # 添加一个新元素
删除元素
unset fruits[1] # 删除索引为1的元素
2. 关联数组的定义与实践
关联数组使用字符串作为键,适合存储键值对。
定义与初始化
# 声明关联数组
declare -A user
# 初始化
user=(
["name"]="Alice"
["age"]="25"
["city"]="New York"
)
# 逐个赋值
user["name"]="Alice"
user["age"]="25"
user["city"]="New York"
访问元素
echo ${user["name"]} # 输出:Alice
echo ${user["age"]} # 输出:25
遍历数组
for key in "${!user[@]}"; do
echo "$key: ${user[$key]}"
done
获取数组长度
echo ${#user[@]} # 输出:3
添加元素
user["country"]="USA" # 添加一个新键值对
删除元素
unset user["age"] # 删除键为"age"的元素
3. 多维数组的模拟
Bash本身不支持真正的多维数组,但可以通过嵌套数组或使用复合键来模拟。
模拟二维索引数组
declare -a matrix
matrix[0]="1 2 3"
matrix[1]="4 5 6"
matrix[2]="7 8 9"
# 访问元素
row=(${matrix[1]})
echo ${row[1]} # 输出:5
模拟二维关联数组
declare -A matrix
matrix["0,0"]="1"
matrix["0,1"]="2"
matrix["1,0"]="3"
matrix["1,1"]="4"
# 访问元素
echo ${matrix["1,0"]} # 输出:3
4. 稀疏数组的定义与实践
Bash数组支持稀疏存储,即数组的索引可以不连续。
定义与初始化
array=()
array[0]="apple"
array[10]="banana"
访问元素
echo ${array[0]} # 输出:apple
echo ${array[10]} # 输出:banana
获取数组长度
echo ${#array[@]} # 输出:2(只有两个元素)
5. 从文件读取数据到数组
可以将文件内容读取到数组中,方便批量处理。
示例
# 将文件内容逐行读取到数组
mapfile -t lines < filename.txt
# 遍历数组
for line in "${lines[@]}"; do
echo "$line"
done
6. 从命令输出读取数据到数组
可以将命令的输出存储到数组中。
示例
# 将ls命令的输出存储到数组
files=($(ls))
# 遍历数组
for file in "${files[@]}"; do
echo "$file"
done
8. 数组的合并
可以将多个数组合并为一个。
示例
array1=("apple" "banana")
array2=("cherry" "date")
combined=("${array1[@]}" "${array2[@]}")
echo ${combined[@]} # 输出:apple banana cherry date
总结
通过以上实践,可以灵活定义和操作Bash数组。无论是索引数组、关联数组,还是多维数组的模拟,Bash都提供了强大的功能来满足各种需求。掌握这些技巧后,可以显著提升脚本的效率和可读性。
3.1 语法
数组用小括号定义,元素以空格区分,数组元素的索引号从0 开始
stu_lists=(张三 李四 三胖 王二麻 )
3.2 普通数组实践
普通数组,对比 python的 list数据类型理解
获取单个值
#!/bin/bash
# author: www.yuchaoit.cn
stu_lists=(张三 李四 三胖 王二麻 )
echo "提取数组 第1个元素 ${stu_lists[0]}"
echo "提取数组 第2个元素 ${stu_lists[1]}"
echo "提取数组 第3个元素 ${stu_lists[2]}"
echo "提取数组 第4个元素 ${stu_lists[3]}"
# 因此读取数组元素的语法是 ${array_name[index]}
# 如果直接打印数组变量,默认提取第一个元素
echo "$stu_lists"
4.关联数组
Bash中的关联数组是一种特殊的数据结构,它允许使用字符串作为索引来存储和访问数据,以下是对Bash关联数组的详细介绍:
定义与声明
在Bash中,需要使用declare或typeset命令并加上-A选项来声明一个关联数组。例如:
declare -A assoc_array
typeset -A assoc_array
初始化
- 可以在声明的同时进行初始化:
declare -A assoc_array=(["key1"]="value1" ["key2"]="value2") - 也可以在声明后逐个赋值来初始化:
declare -A assoc_array assoc_array["key1"]="value1" assoc_array["key2"]="value2"
访问元素
通过键来访问关联数组中的元素,使用${array_name[key]}的形式。例如:
echo ${assoc_array["key1"]}
获取所有键和值
- 获取所有键:使用
${!array_name[@]}或${!array_name[*]}可以获取关联数组的所有键。例如:keys=${!assoc_array[@]} for key in $keys; do echo $key done - 获取所有值:使用
${array_name[@]}或${array_name[*]}可以获取关联数组的所有值。例如:values=${assoc_array[@]} for value in $values; do echo $value done
获取数组长度
通过${#array_name[@]}可以获取关联数组中键值对的数量。例如:
length=${#assoc_array[@]}
echo $length
删除元素
使用unset命令可以删除关联数组中的元素或整个数组。例如:
# 删除单个元素
unset assoc_array["key1"]
# 删除整个数组
unset assoc_array
应用场景
- 配置参数存储:可以用于存储脚本的配置参数,例如数据库连接信息,键可以是
host、port、user、password等,对应的值就是实际的配置内容。 - 统计数据:在处理文本数据时,可以用来统计某些单词或字符串出现的次数,单词作为键,出现次数作为值。
- 菜单选项关联:在编写菜单程序时,将菜单选项的名称作为键,对应的操作命令或函数作为值,方便根据用户选择执行相应的操作。
bash数组对比Python数据类型
Bash是一种Unix shell和命令语言,而Python是一种高级编程语言。
以下是Bash数组与Python中几种常用数据类型的对比讲解:
数据结构特点
- Bash数组
- Bash数组是一种简单的数据结构,用于存储一系列的元素。它的索引是从0开始的整数,但也支持使用字符串作为索引(关联数组)。
- 数组元素可以是任何类型的数据,包括字符串、数字等,但通常在Bash中主要用于存储和操作文本数据。
- 数组的大小在定义时不需要显式指定,它可以根据需要动态增长。
- Python列表(List)
- Python的列表是一种非常灵活和常用的数据类型,类似于Bash数组,但功能更强大。
它可以存储任意类型的数据,包括数字、字符串、列表、字典等。- 列表的索引也是从0开始的整数,支持正向索引和负向索引。
- 列表具有丰富的方法,用于添加、删除、修改和查找元素等操作。
- 切片,取头不取尾
- Python元组(Tuple)
- 元组与列表类似,但元组是不可变的,即一旦创建,就不能修改其元素。
- 元组通常用于存储一组相关的数据,这些数据在程序运行过程中不应该被修改,例如坐标点、RGB颜色值等。
- Python字典(Dictionary)
- 字典是一种键值对的数据结构,类似于Bash中的关联数组。
- 它使用键来访问对应的值,键必须是唯一的,而值可以是任意类型的数据。
- 字典是无序的,不支持通过索引来访问元素,而是通过键来进行查找和操作。
定义和初始化
- Bash数组
- 可以使用以下方式定义和初始化Bash数组:
```bash
普通数组,索引数组
array=(element1 element2 element3)
- 可以使用以下方式定义和初始化Bash数组:
```bash
关联数组
declare -A assoc_array assoc_array[key1]=value1 assoc_array[key2]=value2
- **Python列表**
```python
list1 = [1, 2, 3, 'four', 'five']
# range 取头不取尾,左开右闭
list2 = list(range(1, 6))
- Python元组
tuple1 = (1, 2, 3, 'four', 'five') tuple2 = tuple(range(1, 6)) - Python字典
dict1 = {'key1': 'value1', 'key2': 'value2'} dict2 = dict([('key1', 'value1'), ('key2', 'value2')])
访问和操作元素
- Bash数组
```bash
访问普通数组元素
echo ${array[0]}
访问关联数组元素
echo ${assoc_array[key1]}
修改元素
array[1]=new_element assoc_array[key2]=new_value
获取数组长度
echo ${#array[@]}
- **Python列表**
```python
# 访问元素
print(list1[0])
# 修改元素
list1[1] = 'new_element'
# 添加元素
list1.append('six')
# 删除元素
del list1[2]
# 获取列表长度
print(len(list1))
- Python元组
```python
访问元素
print(tuple1[0])
由于元组不可变,以下操作会报错
tuple1[1] = 'new_element'
- **Python字典**
```python
# 访问元素
print(dict1['key1'])
# 修改元素
dict1['key2'] = 'new_value'
# 添加元素
dict1['key3'] = 'value3'
# 删除元素
del dict1['key1']
# 获取字典长度
print(len(dict1))
应用场景
- Bash数组
- 通常用于Shell脚本中,处理命令行参数、文件列表、配置选项等简单的数据集合。
- 例如,在一个备份脚本中,可以使用Bash数组来存储要备份的文件和目录列表。
- Python列表
- 在Python编程中广泛应用于各种场景,如数据处理、算法实现、Web开发等。
- 可以用于存储用户输入、数据库查询结果、生成随机数列表等。
- Python元组
- 常用于函数返回多个值、打包和解包数据、作为字典的键等场景。
- 例如,在一个图形绘制程序中,可以使用元组来表示图形的坐标和尺寸。
- Python字典
- 适用于需要根据键来快速查找和访问数据的场景,如配置文件解析、统计数据、缓存数据等。
- 例如,在一个Web应用中,可以使用字典来存储用户的登录信息、网站配置参数等。
5.数组取值语法小结
#!/bin/bash
# author: www.yuchaoit.cn
echo ${!stu_info[*]} # 获取数组所有索引
echo ${!stu_info[@]} # 获取数组所有索引
echo ${stu_info[@]} # 获取数组所有元素
echo ${stu_info[*]} # 获取数组所有元素
echo ${#stu_info[*]} # 获取数组所有元素个数
echo ${#stu_info[@]} # 获取数组所有元素个数
echo ${stu_info[key]} # 根据key,提取value
bash运维脚本
在运维生产环境中,Bash 数组可用于多种场景,比如批量处理文件、服务管理、IP 地址管理等。以下是几个使用 Bash 数组的运维生产脚本示例。
1. 批量重启服务脚本
这个脚本使用数组存储需要重启的服务名称,然后遍历数组依次重启每个服务。
#!/bin/bash
# 定义要重启的服务数组
services=("nginx" "mysql" "redis")
# 遍历数组,重启每个服务
for service in "${services[@]}"; do
systemctl restart $service
if [ $? -eq 0 ]; then
echo "$service 服务重启成功"
else
echo "$service 服务重启失败"
fi
done
代码解释:
services数组存储了要重启的服务名称。- 使用
for循环遍历数组中的每个服务名称。 - 调用
systemctl restart命令重启服务,并根据命令的返回值($?)判断重启是否成功。
2. 批量备份文件脚本
该脚本使用数组存储需要备份的文件路径,然后将这些文件复制到指定的备份目录。
#!/bin/bash
# 定义要备份的文件数组
files=("/etc/nginx/nginx.conf" "/etc/mysql/my.cnf" "/var/www/html/index.html")
# 定义备份目录
backup_dir="/backup/files"
# 创建备份目录(如果不存在)
mkdir -p $backup_dir
# 遍历数组,备份每个文件
for file in "${files[@]}"; do
if [ -f $file ]; then
cp $file $backup_dir/
if [ $? -eq 0 ]; then
echo "$file 备份成功"
else
echo "$file 备份失败"
fi
else
echo "$file 文件不存在,跳过备份"
fi
done
代码解释:
files数组存储了要备份的文件路径。backup_dir变量指定了备份文件的目标目录。- 使用
mkdir -p命令创建备份目录(如果不存在)。 - 遍历数组,检查文件是否存在,如果存在则复制到备份目录,并根据复制命令的返回值判断备份是否成功。
3. 批量检查 IP 连通性脚本
此脚本使用数组存储要检查的 IP 地址,然后使用 ping 命令检查每个 IP 的连通性。
#!/bin/bash
# 定义要检查的 IP 数组
ips=("192.168.1.100" "192.168.1.101" "192.168.1.102")
# 遍历数组,检查每个 IP 的连通性
for ip in "${ips[@]}"; do
ping -c 3 $ip > /dev/null 2>&1
if [ $? -eq 0 ]; then
echo "$ip 可以连通"
else
echo "$ip 无法连通"
fi
done
代码解释:
ips数组存储了要检查的 IP 地址。- 使用
ping -c 3命令向每个 IP 地址发送 3 个 ICMP 数据包,并将输出重定向到/dev/null。 - 根据
ping命令的返回值判断 IP 是否可以连通。
脚本使用注意事项
- 权限问题:确保脚本有执行权限,可以使用
chmod +x script.sh命令添加执行权限。 - 错误处理:在实际生产环境中,可能需要更复杂的错误处理机制,例如记录日志、发送警报等。
- 环境适配:不同的系统环境可能会有差异,例如服务管理命令(
systemctl或service),需要根据实际情况进行调整。
bash数组处理nginx日志
以下是一个使用Bash数组来统计Nginx日志的示例脚本,该脚本可以统计不同IP地址的访问次数,以及不同HTTP状态码的出现次数。
需求分析
Nginx日志通常包含多个字段,例如访问的IP地址、时间、请求方法、URL、HTTP状态码等。我们可以通过解析日志文件,提取出所需的信息(如IP地址和HTTP状态码),并使用Bash数组来统计它们的出现次数。
URL :
HTTP_code:
time:
示例脚本
#!/bin/bash
# 定义Nginx日志文件路径
# 准备案例数据,10万条日志记录
log_file=$1
# 检查日志文件是否存在
if [ ! -f "$log_file" ]; then
echo "日志文件 $log_file 不存在。"
exit 1
fi
# 初始化IP地址和HTTP状态码的关联数组
declare -A ip_count
declare -A status_count
# 逐行读取日志文件
# 循环读取文件数据,没一行存储为数组
while read -r line; do
# 提取IP地址(假设IP地址是日志行的第一个字段)
ip=$(echo "$line" | awk '{print $1}')
# 提取HTTP状态码(假设HTTP状态码是日志行的第9个字段)
status=$(echo "$line" | awk '{print $9}')
# 统计IP地址的访问次数
# 期望数组,关联数组,key是ip地址,value是出现次数,数组ip统计
# 如果变量为空,说明ip还没记录
# 否则,说明该ip已经有记录了,进入++操作,出现次数+1
if [[ -n "${ip_count[$ip]}" ]]; then
# 循环对结果+1 赋值
((ip_count[$ip]++))
else
# 既然ip不存在,这里进行初始化,第一次记录
# 数组,变成
ip_count[$ip]=1
fi
# 统计HTTP状态码的出现次数
if [[ -n "${status_count[$status]}" ]]; then
# 该数组,key是状态吗,值是出现次数
((status_count[$status]++))
else
status_count[$status]=1
fi
done < "$log_file"
# 输出IP地址的统计结果
echo "IP地址访问次数统计:"
# ! 提取关联数组的key
for ip in "${!ip_count[@]}"; do
# 循环打印,IP:出现的次数!!
echo "$ip: ${ip_count[$ip]}"
done
# 输出HTTP状态码的统计结果
echo "HTTP状态码出现次数统计:"
for status in "${!status_count[@]}"; do
echo "$status: ${status_count[$status]}"
done
代码解释
- 日志文件检查:脚本首先检查指定的Nginx日志文件是否存在,如果不存在则输出错误信息并退出脚本。
- 关联数组初始化:使用
declare -A命令初始化两个关联数组ip_count和status_count,分别用于统计IP地址的访问次数和HTTP状态码的出现次数。 - 逐行读取日志文件:使用
while read -r line循环逐行读取日志文件,并使用awk命令提取每行中的IP地址和HTTP状态码。 - 统计访问次数:对于提取的IP地址和HTTP状态码,检查它们是否已经存在于对应的关联数组中。如果存在,则将对应的计数器加1;如果不存在,则将计数器初始化为1。
- 输出统计结果:遍历关联数组,输出每个IP地址和HTTP状态码的统计结果。
使用方法
- 将上述脚本保存为一个文件,例如
nginx_log_stats.sh。 - 给脚本添加执行权限:
chmod +x nginx_log_stats.sh。 - 运行脚本:
./nginx_log_stats.sh。
注意事项
- 脚本中假设Nginx日志的格式是常见的格式,即IP地址是日志行的第一个字段,HTTP状态码是日志行的第9个字段。如果你的Nginx日志格式不同,需要相应地调整
awk命令的字段索引。 - 对于大型日志文件,脚本的执行时间可能会比较长。可以考虑使用更高效的工具(如
grep、sort、uniq等)来进行统计。
8.shell数组实践案例
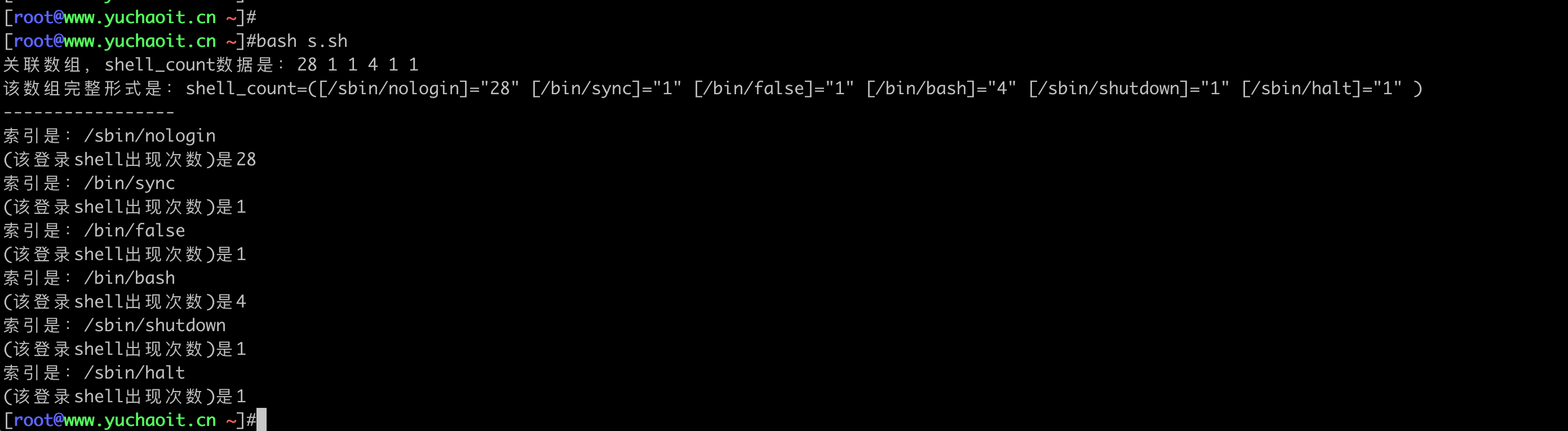
统计/etc/passwd中的登录shell字段出现次数
#!/bin/bash
# author: www.yuchaoit.cn
#
declare -A shell_count
exec </etc/passwd
while read line
do
shell=$(echo $line |awk -F: '{print $NF}')
# 将每一个shell作为key,出现次数作为value
# 在循环体重,同一个shell的话,自增+1
let shell_count[${shell}]++
done
# 打印数组查看
echo "关联数组,shell_count数据是:${shell_count[@]}"
echo "该数组完整形式是:$(set|grep ^shell_count)"
echo '-----------------'
# 循环打印具体的key,value
# 提取所有key,然后根据key获取值
for item in ${!shell_count[@]}
do
echo -e "索引是:$item\n(该登录shell出现次数)是${shell_count[${item}]}"
done
9.使用数组分析Nginx日志
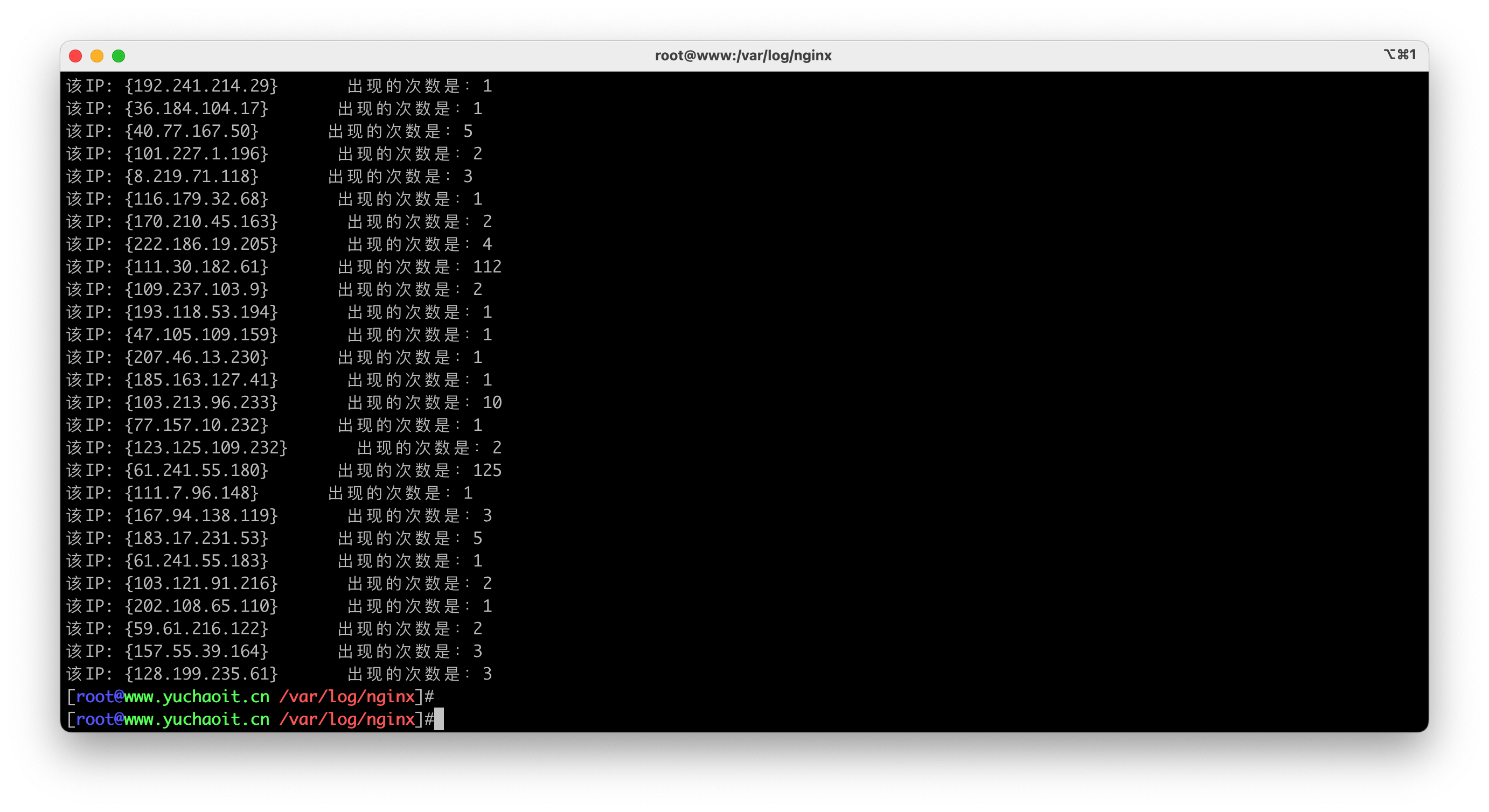
统计Nginx的ip、以及出现次数,保存为关联数组数据。
#!/bin/bash
# author: www.yuchaoit.cn
declare -A ip_count
exec < /var/log/nginx/www.yuchaoit.cn.log
while read line
do
remote_ip=$(echo $line | awk '{print $1}')
# 一样的套路,直接累加赋值
let ip_count[$remote_ip]++
# 写法一个意思
# ip_count[$remote_ip]=$[ ip_count[$remote_ip] + 1]
done
for item in ${!ip_count[@]}
do
echo -e "该IP: {$item} 出现的次数是:${ip_count[${item}]}"
done
10.建议用awk进行统计处理
第九题的shell写法,其实非常耗时。
当我吧文件数据,增加到10万行后,脚本执行的时间,已经很恐怖了。
[root@www.yuchaoit.cn /var/log/nginx]#cat www.yuchaoit.cn.log |wc -l
100000
[root@www.yuchaoit.cn /var/log/nginx]#
[root@www.yuchaoit.cn /var/log/nginx]#time bash s.sh
部分信息
该IP: {59.61.216.122} 出现的次数是:2
该IP: {157.55.39.164} 出现的次数是:199
real 3m27.642s 好家伙,执行了三分钟,这也忒慢了
user 1m38.241s
sys 1m33.042s
[root@www.yuchaoit.cn /var/log/nginx]#
改为awk关联数组写法
real 0m0.002s real 是命令从开始到结束的时间,
user 0m0.000s cpu执行进程耗时
sys 0m0.002s 系统内核执行的耗时
[root@www.yuchaoit.cn /var/log/nginx]#time awk '{ip_count[$1]++} END{for (item in ip_count) print "IP是:" item, "出现次数:" ip_count[item] }' www.yuchaoit.cn.log

所以在我们学完了基础语法后,你会发现,未来的路还很长,除了要完成功能,你还要不断学习,优化程序,考虑效率。
在有现成的工具,优秀的命令,软件,能解决你的问题时;
千万别去自己造轮子,费力不讨好,学习工具,解决问题是第一生产要素。